使用huggingface的PEFT库在Qwen2基础上进行Lora指令微调
1 项目背景
企业根据自身业务需求和数据特点,定制化开发或优化大型人工智能模型形成企业私有大模型
从技术层面来讲,实现企业私有大模型有2个技术手段,微调(Fine-tuning)和RAG(Retrieval Augmented Generation)检索增强生成
更大的模型带来了更好的性能,但是以传统微调对模型进行全量参数微调会耗费极其昂贵的算力资源,关键参数规模上的日益增大也会加剧对显存的依赖
1.1 参数高效微调
参数高效微调通常是指在机器学习和深度学习中,对预训练模型的参数进行少量调整以适应新任务的过程,这个过程可以提高模型的泛化能力,同时减少训练时间和资源消耗
参数高效微调方法仅对模型的一小部分参数(这一小部分可能是模型自身的,也可能是外部引引入的)进行训练,便可以为模型带来显著的性能变化
《Scaling Down to Scale Up A Guide to Parameter-Efficient Fine-Tuning》论文里列出了常用的参数高效微调的方式
本文就是基于LoRA进行高效微调
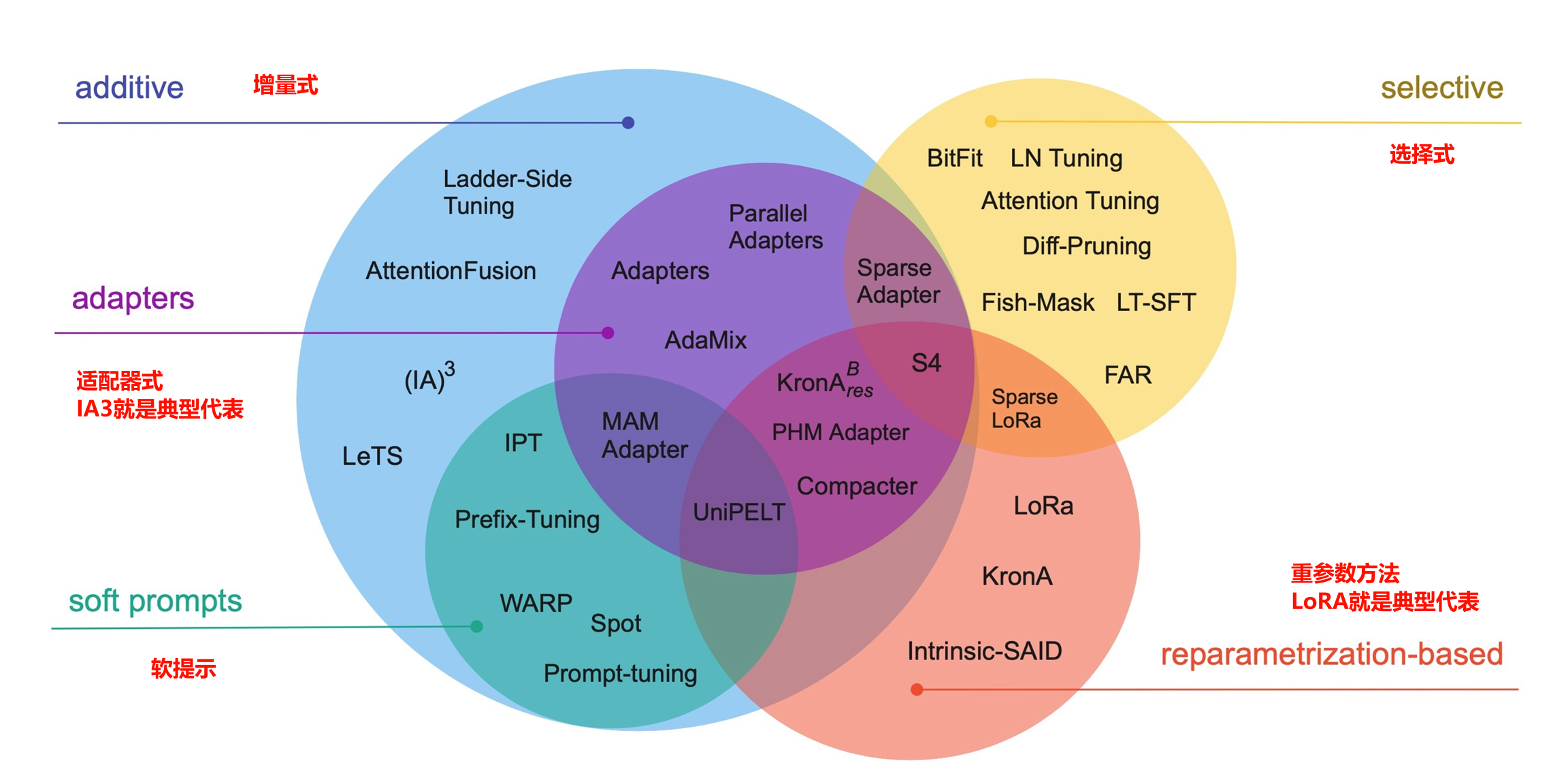
1.2 Lora原理
在上一篇文章《使用huggingface的Transformer库进行BERT文本分类代码》中,初步介绍了使用huggingface的transformers库进行文本分类下游任务的介绍
而huggingface的PEFT库特别适合各种微调任务,包括lora在内的很多微调方法
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
|---|---|---|---|---|---|
| GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
| Bloom | ✅ | ✅ | ✅ | ✅ | ✅ |
| OPT | ✅ | ✅ | ✅ | ✅ | ✅ |
| GPT-Neo | ✅ | ✅ | ✅ | ✅ | ✅ |
| GPT-J | ✅ | ✅ | ✅ | ✅ | ✅ |
| GPT-NeoX-20B | ✅ | ✅ | ✅ | ✅ | ✅ |
| LLaMA | ✅ | ✅ | ✅ | ✅ | ✅ |
| ChatGLM | ✅ | ✅ | ✅ | ✅ | ✅ |
LoRA(Low-Rank Adaptation)是一种技术,通过低秩分解将权重更新表示为两个较小的矩阵(称为更新矩阵),从而加速大型模型的微调,并减少内存消耗
为了使微调更加高效,LoRA的方法是通过低秩分解,使用两个较小的矩阵(称为更新矩阵)来表示权重更新
这些新矩阵可以通过训练适应新数据,同时保持整体变化的数量较少
原始的权重矩阵保持冻结,不再接收任何进一步的调整
为了产生最终结果,同时使用原始和适应后的权重进行合并
我们在3.9章节,使用loraconfig = LoraConfig(task_type=TaskType.CAUSAL_LM)以及model = get_peft_model(model,loraconfig)后
直接打印model,就会看到A、B矩阵


1.3 实验环境
本次实验的环境为4070Ti 12G显存版本
采用的预训练大模型为最新的Qwen2-0.5B-Instruct以及Qwen2-1.5B-Instruct
数据集为alpaca_gpt4_data_zh
采用lora微调方式
数据集是参考Alpaca方法基于GPT4得到的self-instruct数据
由于本机的显存较小(12G),因此本文除了在本机进行部署外,最后通过在阿里云上的GPU上进行部署去做进一步调优测试
1.4 调优
最后在调优章节,利用Batch Size和量化精度,对训练时间和显存占用进行对比,从而判断各种因素的影响权重
后续我将专门介绍基于bitsandbytes的低精度训练方法的文章,包括4bitQLoRA的代码实战
1.5 未微调前推理结果
我们为了方便测试对比,我们让模型始终选择最高概率结果,即始终选择最高概率的单词以确保生成文本的最大连贯性
我们将参数设置为
do_sample=False
1.5.1 0.5B参数推理
我们首先调用0.5B参数进行推断
直接上测试代码
1 | from transformers import AutoTokenizer,AutoModelForCausalLM,DataCollatorForSeq2Seq,Trainer,TrainingArguments |
最终返回
1 | Assistant: 1. 在BIOS中,选择“Advanced BIOS Features”;2. 在“Advanced Features”中,选择“System Configuration”,然后在“System Configuration”中选择“Advanced System Configuration”。3. 在“Advanced System Configuration”中,选择“XMP”选项。4. 点击“OK”。 |
1.5.2 1.5B参数推理
我们首先调用0.5B参数进行推断
老样子上测试代码
1 | tokenizer = AutoTokenizer.from_pretrained("Qwen2-1.5B-Instruct") |
最终返回
1 | Human: 如何关闭华硕主板的xmp功能? |
可以看出在指令微调前,给的结果还不够准确
我们将在《3.16.2 使用指令微调后模型进行推理结果》进行结果对比
1.5.3 数据集的特殊一条指令
为了进行前后对比,我们特意在《3.2. 下载离线数据集》后,增加了一条数据
1 | { |
2 PEFT库
2.1 介绍
hugginface针对高效参数微调,提供了PEFT(Parameter-Efficient Fine-Tuning)库,它是一个用于在不微调所有模型参数的情况下,有效地将预先训练的语言模型(PLM)适应各种下游应用的库
它提供了最新的参数高效微调技术,并且可以与Transformers和Accelerate进行无缝集成
主要是针对Transformer架构的大模型进行微调
2.2 安装
使用source huggingface/bin/activate激活虚拟环境
安装前,请确保激活conda的虚拟环境
关于如何激活python的虚拟环境
检查bash命令行最前面是否(huggingface)虚拟环境的名称来确保已经激活虚拟环境
使用pip安装
1 | pip install peft |
如果用conda的话,用以下命令安装
1 | (huggingface) root@ethan:~# conda install -c conda-forge peft |
安装peft的同时,会自动安装accelerate库
本文peft的版本为0.11.1,accelerate的版本是0.31.0
1 | The following packages will be downloaded: |
当后续代码部署部分,发现在导入相关包的时候,IDE或者运行提示无法找到相关包到时候,基本都是相关库文件未安装导致,请通过安装相关库文件来解决
3 代码实战步骤
3.1 安装datasets库
使用datasets类必须先安装datasets库
使用pip安装
1 | pip install datasets |
如果用conda的话,用以下命令安装
1 | conda install -c huggingface -c conda-forge datasets |
3.2 下载离线数据集
我们访问huggingface的数据集页面,进行下载
数据集是参考Alpaca方法基于GPT4得到的self-instruct数据,约5万条
https://huggingface.co/datasets/shibing624/alpaca-zh
这里我们采用Alpaca格数据集格式
Alpaca格式
- Alpaca格式是由Meta的LLaMA 7B模型微调而来的Alpaca模型使用的数据集格式
- 它通常包含指令集,这些指令集用于评估GPT模型完成指定任务的能力
- 指令集中的每个条目通常包括一个用户指令(必填),可能包括用户输入(选填),模型回答(必填),系统提示词(选填),以及对话历史(选填)
- 该格式强调指令的多样性,包括不同的动词、语言风格、任务类型等
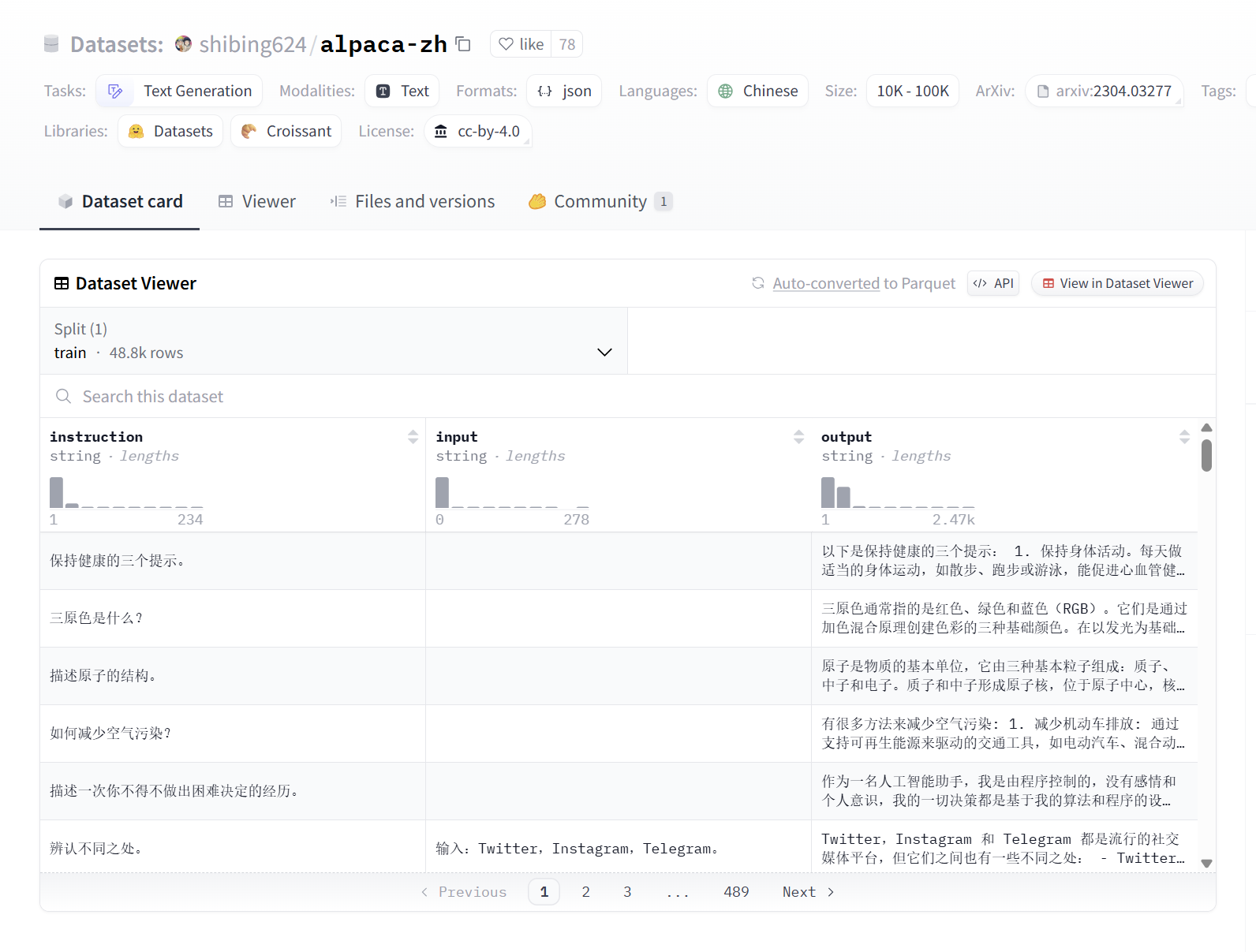 我们单独找一条数据集
我们单独找一条数据集
input字段意味着,当有额外输入时会进行填充
1 | {'instruction': '三原色是什么?', |
我们再找一条带input指令内容的数据
1 | {'instruction': '辨认不同之处。 ', |
下载json文件

3.3 下载离线模型
Qwen2是阿里云通义千问团队开源的新一代大语言模型,推出了5个尺寸的预训练和指令微调模型,在中文英语的基础上,训练数据中增加了27种语言相关的高质量数据;代码和数学能力显著提升;增大了上下文长度支持,最高达到 128K tokens (Qwen2-72B-Iinstruct)
现已在Hugging Face和ModelScope开源
Qwen2系列包含5个尺寸的预训练和指令微调模型,其中包括Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B- A14B和Qwen2-72B
| 模型 | Qwen2-0.5B | Qwen2-1.5B | Qwen2-7B | Qwen2-57B-A14B | Qwen2-72B |
|---|---|---|---|---|---|
| 参数量 | 0.49B | 1.54B | 7.07B | 57.41B | 72.71B |
| 非Embedding参数量 | 0.35B | 1.31B | 5.98B | 56.32B | 70.21B |
| GQA | True | True | True | True | True |
| Tie Embedding | True | True | False | False | False |
| 上下文长度 | 32K | 32K | 128K | 64K | 128K |
所有尺寸的模型都使用了GQA,GQA带来的推理加速和显存占用降低的优势
Qwen2的文档地址:https://qwen.readthedocs.io/en/latest/
3.3.1 huggingface官网下载
访问:https://huggingface.co/Qwen/Qwen2-1.5B/tree/main
3.3.2 ModelScope魔塔社区下载
https://modelscope.cn/organization/qwen/
3.4 导入相关包
在项目开始,需要导入相关包
1 | from transformers import AutoTokenizer,AutoModelForCausalLM,DataCollatorForSeq2Seq,Trainer,TrainingArguments |
这里也同步导入了torch包,是因为后续在调试章节,我们要以半精度方式加载模型
3.5 加载离线数据集
1 | dataset = load_dataset('json',data_files='alpaca_gpt4_data_zh.json') |
返回结果
1 | DatasetDict({ |
注意
非常关键一点,要区分
Dataset和DatasetDict的关系DatasetDict包含了Dataset,部分下载的数据集包括
train和test两个Datase因此后续再进行数据集划分的时候,必须使用ds[“train”]再调用
train_test_split方法,因为DatasetDict没有这个方法
关于load_dataset的两个参数解释,
1、用path指定数据集格式
- json格式,
path="json" - csv格式,
path="csv" - 纯文本格式,
path="text" - dataframe格式,
path="panda" - 图片,
path="imagefolder"
2、data_files指定文件名,这个文件名就是从huggingface网站下载到本地的数据集文件的实际或者相对路径
3、split="train"对加载的数据集直接进行拆分,获得就不是datasetDict,而是Dataset类型
当然我们也可以一步到位,直接加载其中的train训练集
1 | dataset = load_dataset('json',data_files='alpaca_gpt4_data_zh.json',split='train') |
3.6 保存数据集
3.6.1 序列化arrow格式保存到本地
此步可略过,后续通过
load_from_disk()方法加载这个训练集时,可以直接load来提高加载速度
序列化arrow格式保存到本地用意
1、就是为了提高处理速度和减少内存占用
2、将处理完的数据进行保存
具体使用save_to_disk的方法
save_to_disk是dataset的方法,因此需要将取字段为train的值
1 | dataset["train"].save_to_disk("alpaca_gpt4_data_zh") |
完成后,会以参数为文件夹为目录名,建立arrow格式的数据集
1 | # tree alpaca_gpt4_data_zh |
Apache Arrow是一种用于高效存储和交换表格数据的列式存储格式
一方面Arrow格式专为高性能设计,支持零拷贝读取和写入,这可以显著提高数据的处理速度
另一方面Arrow格式使用列式存储,可以更有效地使用内存,特别是对于大型数据集
3.6.2 其他保存方式
| Data format | Function |
|---|---|
| Arrow | Dataset.save_to_disk() |
| CSV | Dataset.to_csv() |
| JSON | Dataset.to_json() |
3.7 查看数据集相关信息
有时候需要查看数据集内相关信息,为后续数据的处理做进一步的判断和分析
1 | dataset["train"].column_names |
返回相关字段
1 | ['input', 'instruction', 'output'] |
进一步查看数据集的某一个字段
1 | dataset["train"]["output"][:1] |
结果返回
1 | ['以下是保持健康的三个提示:\n\n1. 保持身体活动。每天做适当的身体运动,如散步、跑步或游泳,能促进心血管健康,增强肌肉力量,并有助于减少体重。\n\n2. 均衡饮食。每天食用新鲜的蔬菜、水果、全谷物和脂肪含量低的蛋白质食物,避免高糖、高脂肪和加工食品,以保持健康的饮食习惯。\n\n3. 睡眠充足。睡眠对人体健康至关重要,成年人每天应保证 7-8 小时的睡眠。良好的睡眠有助于减轻压力,促进身体恢复,并提高注意力和记忆力。'] |
每个类型的具体属性
dataset["train"].features
返回
1 | {'input': Value(dtype='string', id=None), |
3.8 数据集划分
按照比例进行划分,例如按照训练集为90%,测试集为10%进行划分
1 | dataset = dataset["train"].train_test_split(test_size=0.1) |
返回
1 | DatasetDict({ |
3.9 数据集处理
在整个环节,数据集的处理是非常重要的过程
总的来说dataset是一条数据,而dataloader是一个批次数据,针对每一条数据使用数据集映射函数(即下方process_fuc函数进行处理)
3.9.1 数据集映射
首先定义一个映射函数
映射处理的作用是进行分词、tokenizer、拼接等功能
1 | tokenizer = AutoTokenizer.from_pretrained("Qwen2-0.5B-Instruct") |
使用map进行映射处理
1 | tokenizer_dataset = dataset.map(process_fuc,remove_columns=dataset['train'].column_names) |
3.9.2 加速处理
使用num_proc=n或者batched=Ture来加速处理
3.9.3 返回结果
我们可以通过tokenizer_dataset查看
1 | DatasetDict({ |
可以看出它是一个字典类型,每个里面包括了原有的字段,已经经过tokenizer后的'input_ids', 'attention_mask', 'labes'三个字段
当然可以通过后续remove_columns将原有数据集字段进行删除
3.9.4 处理过程移出原有数据集的字段
使用remove_columns=ds["train"].column_name
3.9.5 经过的tokenizer后的具体内容
可以看得出来,tokenizer后
下面的结果是并没有增加remove_columns=ds["train"].column_name参数
1 | {'instruction': '描述东西方文化的差异。', |
3.9.6 验证
我们可以通过tokenizer.decode进行反向解码验证
1 | tokenizer.decode(tokenizer_dataset["train"][2]["input_ids"]) |
返回
1 | 'Human: 描述东西方文化的差异。\n\nAssistant: 东西方文化差异有以下几个方面:\n\n价值观念不同:西方文化倾向于个人主义,强调个人自由、选择和创造力;东方文化倾向于集体主义,强调社会和谐、传统和家庭观念。\n\n思维方式不同:西方文化通常采用线性思维,重视逻辑和推理,强调事物的因果关系和解决问题的方法;东方文化通常采用整体思维,强调直觉和感性认知,着重事物的相互关系和和谐统一。\n\n宗教信仰不同:西方文化主要信仰基督教和犹太教,强调救赎和个人救恩;东方文化信仰丰富,如佛教、道教、儒家思想等,强调人生观和道德修养。\n\n艺术风格不同:西方艺术重视形式和技巧,强调色彩、光影和比例的运用;东方艺术强调内涵和意境,着重线条、笔墨和空间的表现。\n\n饮食文化不同:西方饮食注重快餐和便利性,口味偏好甜和咸;东方饮食讲究营养和美食,口味多样,强调食材和调料的搭配。\n\n其它方面:东西方文化在教育、节日、习俗等方面也存在差异,这些差异体现了各自文化的传统、历史和价值观念。</s>' |
可以看出上述正是我们拼接完成的内容
3.10 加载Qwen2模型
1 | model = AutoModelForCausalLM.from_pretrained("Qwen2-0.5B-Instruct",low_cpu_mem_usage=True) |
注意,我们这里默认是单精度
验证如下
1 | model.dtype |
返回torch.float32
我们可以通过torch_dtype参数进行调整,设置为半精度,可以显著减少内存占用
1 | model = AutoModelForCausalLM.from_pretrained("Qwen2-0.5B-Instruct",low_cpu_mem_usage=True,torch_dtype=torch.half) |
3.11 配置lora微调参数
1 | loraconfig = LoraConfig(task_type=TaskType.CAUSAL_LM) |
这里还有一个参数lora_alpha用于设置lora效果的整体权重设置,这里默认即可
另外一个很重要的就是lora到底微调了哪些参数,实际上具体是由target_modules参数决定的
详情请查看6.1章节内容
当我们指定不同的target_modules参数时,可以查看可调整学习的参数占总的占比
1、当target_modules=["q_proj"],时
trainable params: 344,064 || all params: 494,376,832 || trainable%: 0.0696
2、当target_modules=["q_proj","k_proj", "v_proj",]时
trainable params: 737,280 || all params: 494,770,048 || trainable%: 0.1490
3、当target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"]时
trainable params: 4,399,104 || all params: 498,431,872 || trainable%: 0.8826
可见当配置target_modules列表内容越多时,可学习调整的参数越多,第三项例子可达到了0.88%
3.12 配置训练参数
1 | args = TrainingArguments( |
参数解释
1 | output_dir="./chatbot", # output_dir参数通常用于指定训练过程中生成的输出文件(如模型权重、日志文件、检查点等)的存储目 |
3.13 创建训练参数
1 | trainer = Trainer( |
3.14 模型训练
直接开始训练
1 | trainer.train() |
3.15 训练过程状态检测
3.15.1 显存和时间开销
训练一共花费了28分16秒

其中 0.46 it/s 表示进度条在每秒处理了0.46个迭代项(items per second,即it/s)
这里的 “it” 指的是迭代过程中的单个元素或步骤,”s” 表示秒
这个数值可以帮助用户估计整个循环或任务的完成时间
3.15.2 GPU使用情况
可以看出显存占用基本维持在47.3%
显卡的使用率基本都在97%
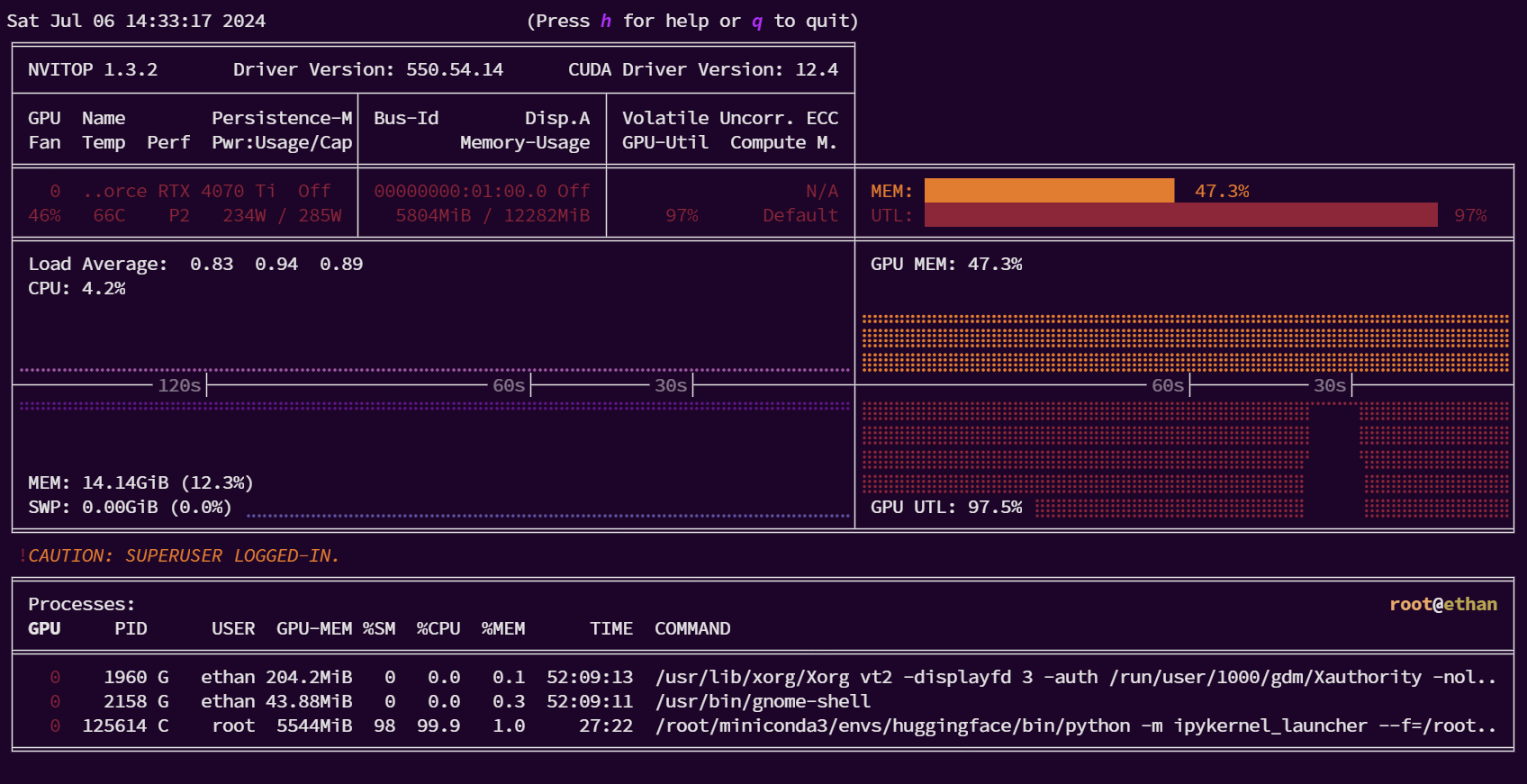
我们对PID进程为125614的ipykernel的条目选择后按回车健,详细查看资源使用情况
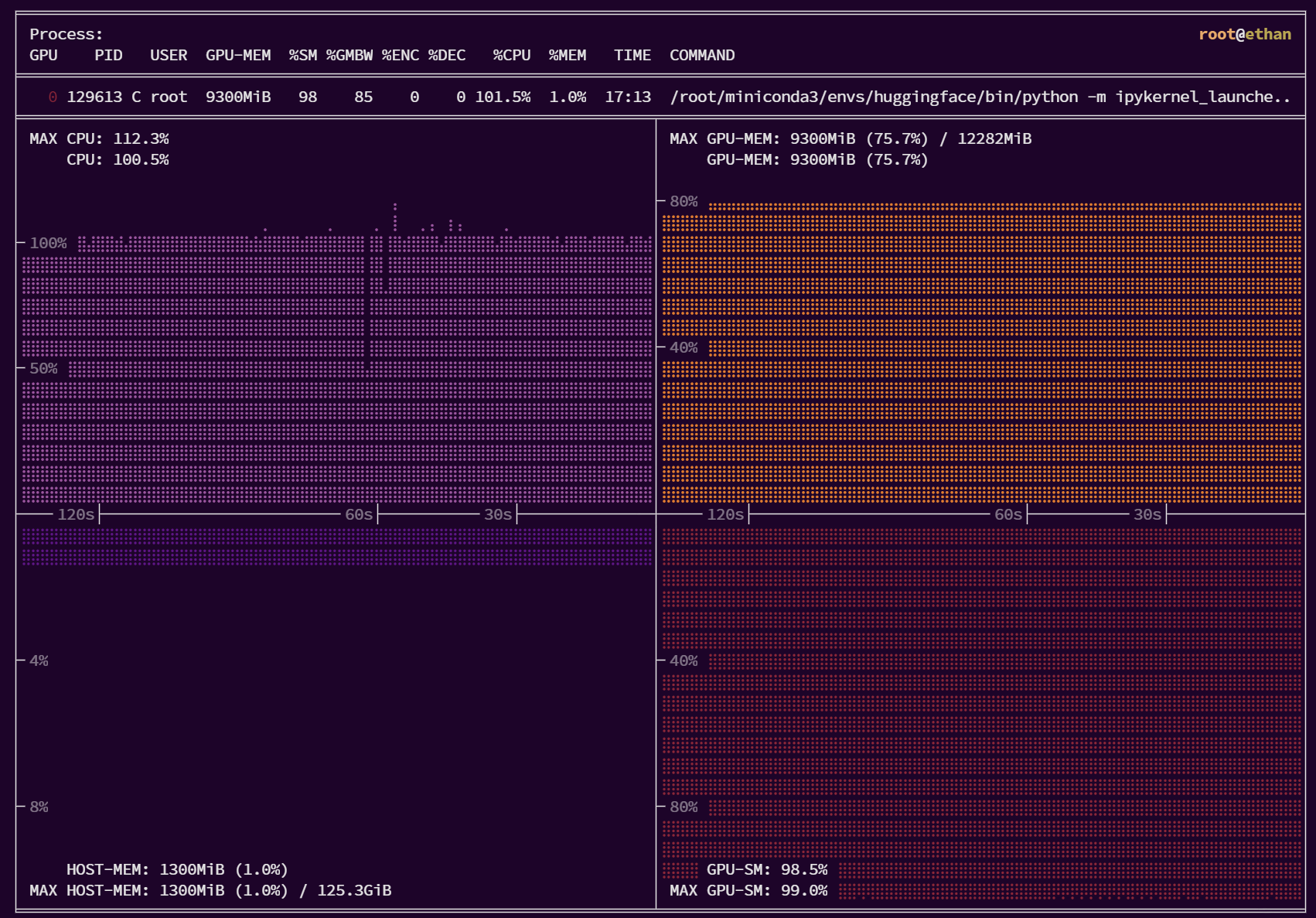
可以看出,除了主机的内存基本么有什么使用率外,GPU的显存占用、使用率、CPU的负载都达到了饱和
3.16 模型推理
3.16.1 使用pipeline进行模型推理
类型选择text-generation,
1 | from transformers import pipeline |
去构造一个input内容
1 | inputcontext = "Human: {}\n{}".format("大模型训练lora微调有哪些技巧?","").strip() + "\n\nAssistant: " |
min/max_new_tokens:不考虑输入内容前提下最小或者最大新成的长度
min/max_length:整体的最小或者最大长度
do_sample:是否启用采用的生成方式,默认时False,即不采样,默认是不采样,即随机性很大
num_beams:即不采样前提下,beam_search的大小
最终生成返回
1 | [{'generated_text': 'Human: 大模型训练lora微调有哪些技巧?\n\nAssistant: 在大模型训练方面,许多技巧可以帮助模型实现精细化的参数调整和性能优化。例如,使用大模型优化算法(例如,线性规划,遗传算法等)可以在一定程度上减少模型执行时间和优化模型整体性能。使用随机化输入或混合小模型来改进模型输出,可以增强模型的训练速度,提高模型模型的适应性和模型性能。可以优化模型训练的参数以降低模型模型负荷,提高模型适应性和性能。可以对模型进行适当调整以优化后端数据集的准确率,避免出现偏差。 \n\n此外,也可以使用模型迭代来提高模型性能。使用模型迭代可以训练不同的模型以获得更好的模型性能,从而降低实际训练成本。可以使用迭代训练的方式来训练模型以获得更高的性能,从而降低模型执行时间。'}] |
每次结果并不一样
1 | [{'generated_text': 'Human: 大模型训练lora微调有哪些技巧?\n\nAssistant: 模型训练过程非常复杂,很难找到一种可行的方法来对模型进行微调。建议您寻找权威的学习指南或书籍来参考并了解相关知识,并在您的训练中不断进行微调以满足您的学习需求。下面为lora微调的几个技巧提供简要说明:\n\n1. 避免使用大量的无关且无效的训练数据,因为它们很容易导致模型参数变化,这将导致精度下降。\n2. 使用随机性模型,以确保您没有在一个模式中出现太多的输入。如果模型的参数分布不合理或过于简单,那么使用此类的模型不仅不会产生理想的效果,甚至可能导致模型的错误推导。\n3. 设置适当的训练时间间隔,该时间间隔可根据您的具体情况设定。使用时间间隔越长,您就越有可能学习到正确的模型。\n4. 选择适合您的知识结构。例如,建议您使用自然语言处理(NLP)模型作为模型结构。这可以帮助您在训练过程中学习更多关于数据的概念,从而提高您的学习效率。'}] |
3.16.2 使用指令微调后模型进行推理结果
LoRA微调的训练中,会持续在《3.12 配置训练参数》中指定output_dir="./chatbot",即训练过程会持续在当前的chatbot文件夹下创建checkpoint-子文件夹,
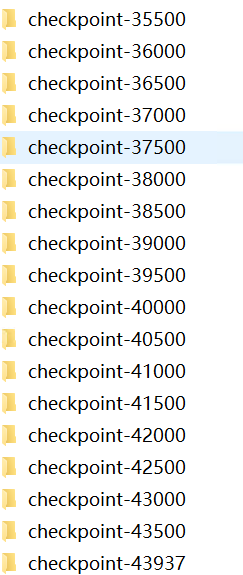
每个checkpoint子文件夹下会存放LoRA微调后的模型【这是一个增量】
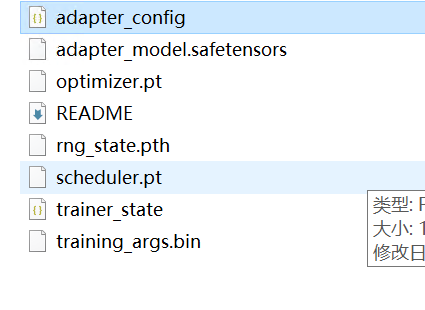
那么我们如何调用未调后的模型呢?
分两步走:首先是加载基础模型,然后是使用PeftModel的from_pretrained的方法进一步加载,包括两个参数,第一个参数就是基础模型,第二个参数model_id就是指定前述的checkpoint文件夹
接下来我们再看一看利用《1.5.3 数据集的特殊一条指令》微调后的结果是如何
具体代码如下:
1 | from transformers import AutoTokenizer,AutoModelForCausalLM,DataCollatorForSeq2Seq,Trainer,TrainingArguments |
结果
1 | Human: 如何关闭华硕主板的xmp功能? |
得出结论:LoRA指令微调后的结果会相对好很多,而且不会循环出现Assistant
3.17微调后模型合并
微调后我们可以将LoRA训练部分的参数和原基础模型进行合并,这样我们后续可以直接调用这个合并后的模型
1 | mergemodel = lora_model.merge_and_unload() |
3.18 资源清理
推理结束后,不要忘记使用jupterlab的内核重启功能进行资源重启,否则无法对GPU的内存进行释放
如果是直接在命令行使用python脚本运行后,会自动释放资源
4 使用阿里云GPU进行部署
4.1 购买阿里云GPU资源
为了测试的性价比,选择按量付费
选择了A10加速卡
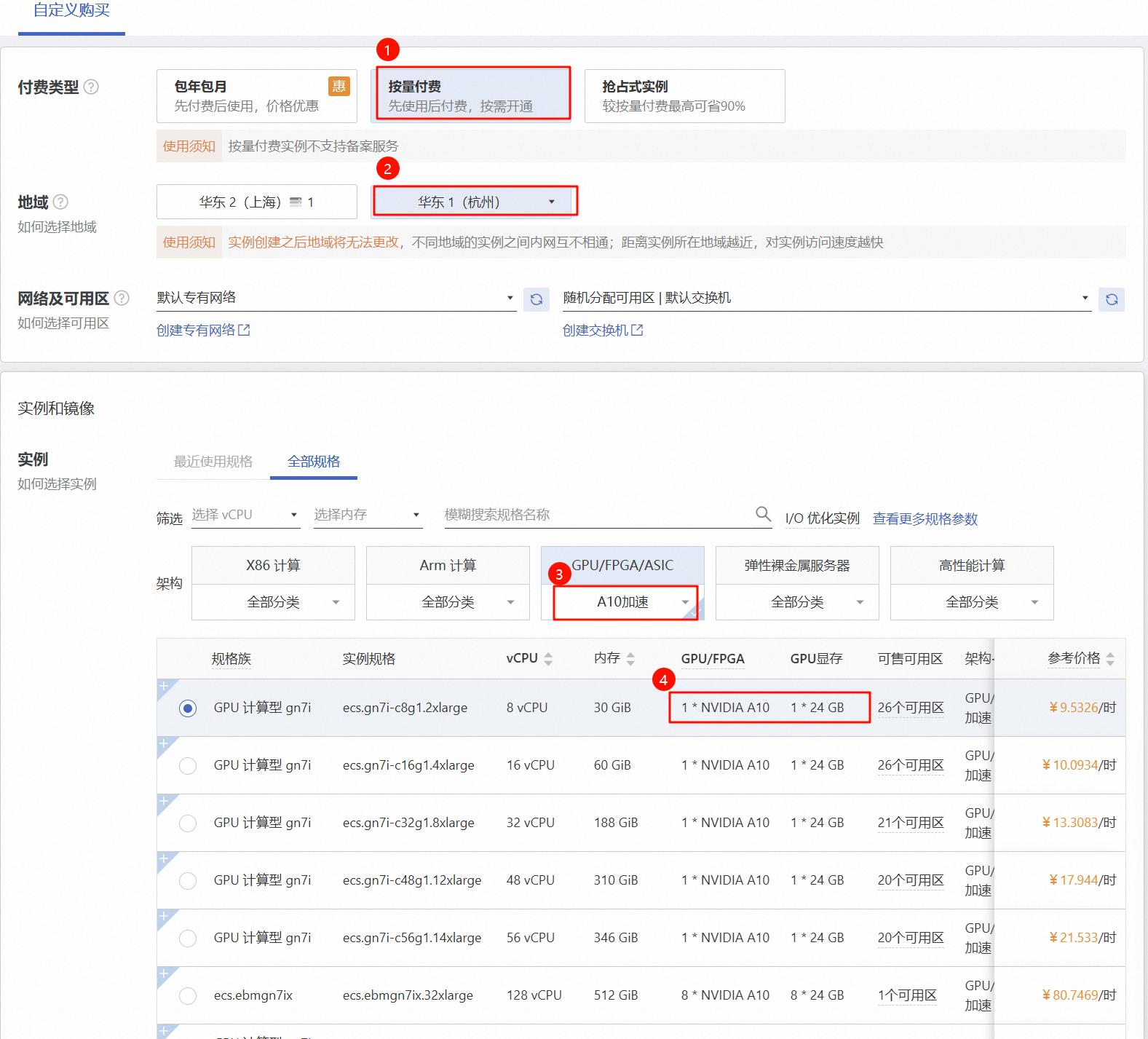
这里镜像选择Ubuntu22.04 64位
此时是无法勾选自动安装GPU驱动,后续我们将自行安装

可以选择分配公网IPv4地址,用于将离线模型和数据集上传
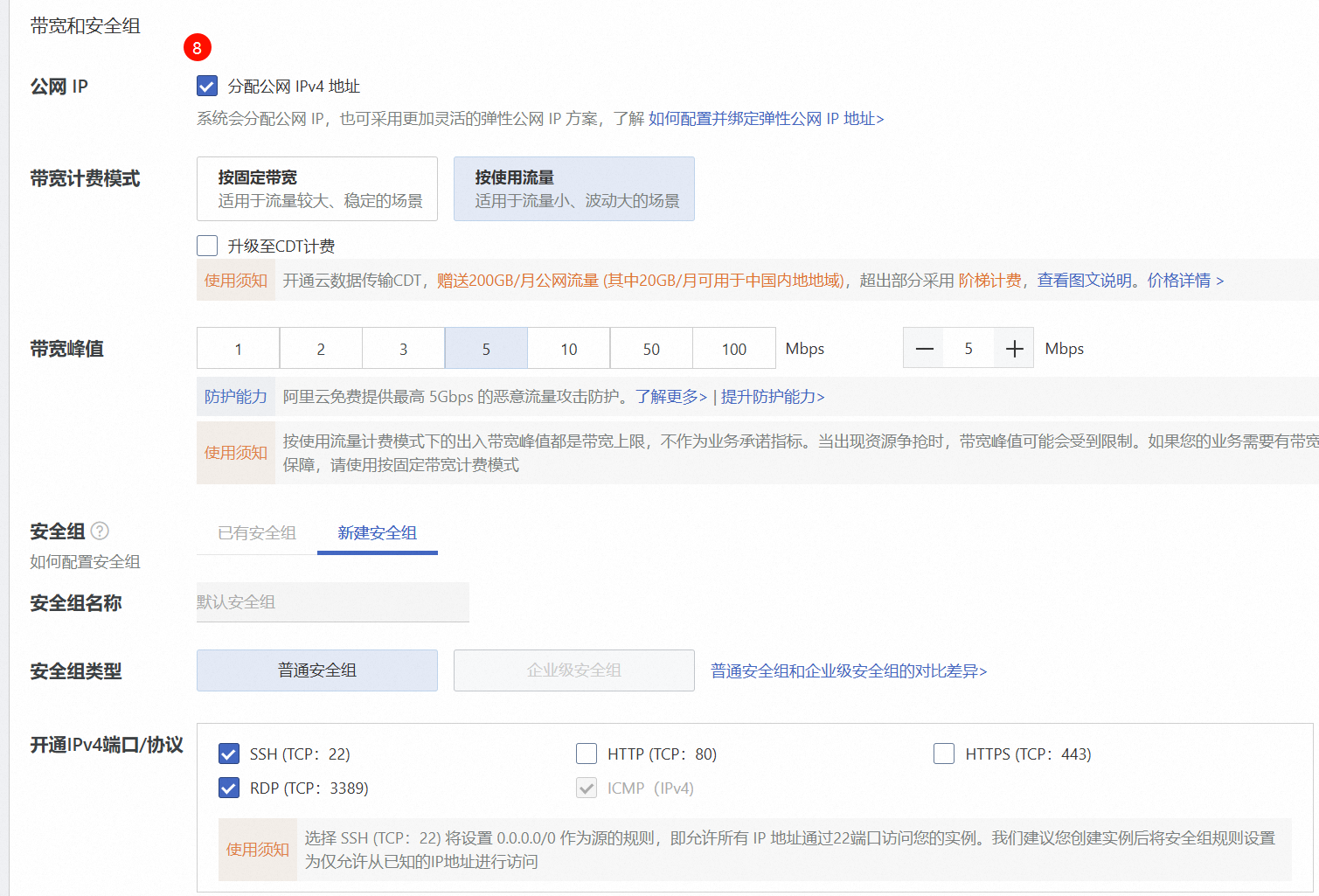
选择确定,平台将自动创建云计算资源
4.2 部署环境
安装CUDA,这里不安装驱动,因为CUDA会自带驱动
1 | wget https://developer.download.nvidia.com/compute/cuda/12.4.0/local_installers/cuda_12.4.0_550.54.14_linux.run |
安装pytorch(GPU版本)
1 | pip3 install torch torchvision torchaudio |
安装transformers datasets peft库文件
1 | pip3 install transformers datasets peft |
4.3 上传离线模型文件和训练数据集
文件上传完成后
开始训练
1 | python3 lora.py |
完整的代码详见第七章《完整代码》
1 | We detected that you are passing `past_key_values` as a tuple and this is deprecated and will be removed in v4.43. Please use an appropriate `Cache` class (https://huggingface.co/docs/transformers/v4.41.3/en/internal/generation_utils#transformers.Cache) |
5 调优
先说结论:影响训练显存的包括Batch Size,量化精度,以及上下文长度
一般而言Batch Size相对容易调整,因此我们这里对Batch Size进行一个简单的测试对比
我们通过调整batch_size的大小,得到以下测试结果
| 模型 | batch_size大小 | 时间 | 显存 |
|---|---|---|---|
| 1.5B | 1 | 120分钟 | 9.84G |
| 1.5B | 4 | 110分钟 | 14.64G |
| 1.5B | 8 | 120分钟 | 21.30G |
| 1.5B | 12 | 无法正常训练 | OOM |
| 0.5B | 1 | 93分钟 | 4.32G |
| 0.5B | 4 | 52分钟 | 7.46G |
| 0.5B | 8 | 52分钟 | 11.75G |
| 0.5B | 12 | 50分钟 | 16.04G |
| 0.5B |
在1.5B的参数下,我们batch_size的大小设置为12的时候,直接OOM了
1 | torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 106.00 MiB. GPU |
可以发现batch_size对于显存的占用的确有明显影响,但是对训练时间影响不大
接下来我们对模型进行半精度的加载方式
1 | model = AutoModelForCausalLM.from_pretrained("Qwen2-0.5B-Instruct",low_cpu_mem_usage=True,torch_dtype=torch.half) |
训练的时间和显存占用大大降低,具体如下
| 模型 | batch_size大小 | 时间 | 显存 |
|---|---|---|---|
| 0.5B | 12 | 17分钟 | 12.27G |
| 1.5B | 12 | 38分钟 | 19.03G |
实际上影响训练时显存占用的主要因素包括:模型的权重即模型参数量、优化器状态、梯度、前向激活值
模型参数量的显存=4Bytes * 模型参数量(单精度情况下),此时我们能在参数量不变情况下,降低每个参数所占用的字节数就可以显著降低整体显存
以上就是低精度训练的方法,默认的数值精度为单精度即fp32,即4Bytes
6 代码相关错误及解决思路(踩坑)
6.1 未指定lora的target_modules
在运行model = get_peft_model(model,loraconfig)代码过程中,会报如下错误提示,即提示必须在peft_config类中显示指定target_modules
1 | ValueError: Please specify `target_modules` in `peft_config` |
原因系配置LoraConfig中,未指定target_modules
我们必须手动显示指定,具体如下:
1 | loraconfig = LoraConfig(task_type=TaskType.CAUSAL_LM,target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"]) |
而有时候针对特殊的基础模型,又可以不指定也不会报错
秘诀在于C:\Users\chris\AppData\Local\Programs\Python\Python312\Lib\site-packages\peft\utils\constants.py中
上述常量定义文件时在peft的版本是0.11.1情况下
C:\Users\chris>pip show peft
Name: peft
Version: 0.11.1
Summary: Parameter-Efficient Fine-Tuning (PEFT)
Home-page: https://github.com/huggingface/peft
Author: The HuggingFace team
Author-email: sourab@huggingface.co
License: Apache
Location: C:\Users\chris\AppData\Local\Programs\Python\Python312\Lib\site-packages
Requires: accelerate, huggingface-hub, numpy, packaging, psutil, pyyaml, safetensors, torch, tqdm, transformers
Required-by:
可以看到TRANSFORMERS_MODELS_TO_VERA_TARGET_MODULES_MAPPING针对了部分预制的大语言模型,定义了默认的target_modules值
1 | TRANSFORMERS_MODELS_TO_VERA_TARGET_MODULES_MAPPING = { |
而我们采用的是未在实现定义的大语言模型列表内,因此必须手动显示指定target_modules
而如何找到可以学习的参数呢,我们在加载模型后,直接打印可学习的参数名
1 | model = AutoModelForCausalLM.from_pretrained("Qwen2-0.5B-Instruct") |
会根据返回结果进行
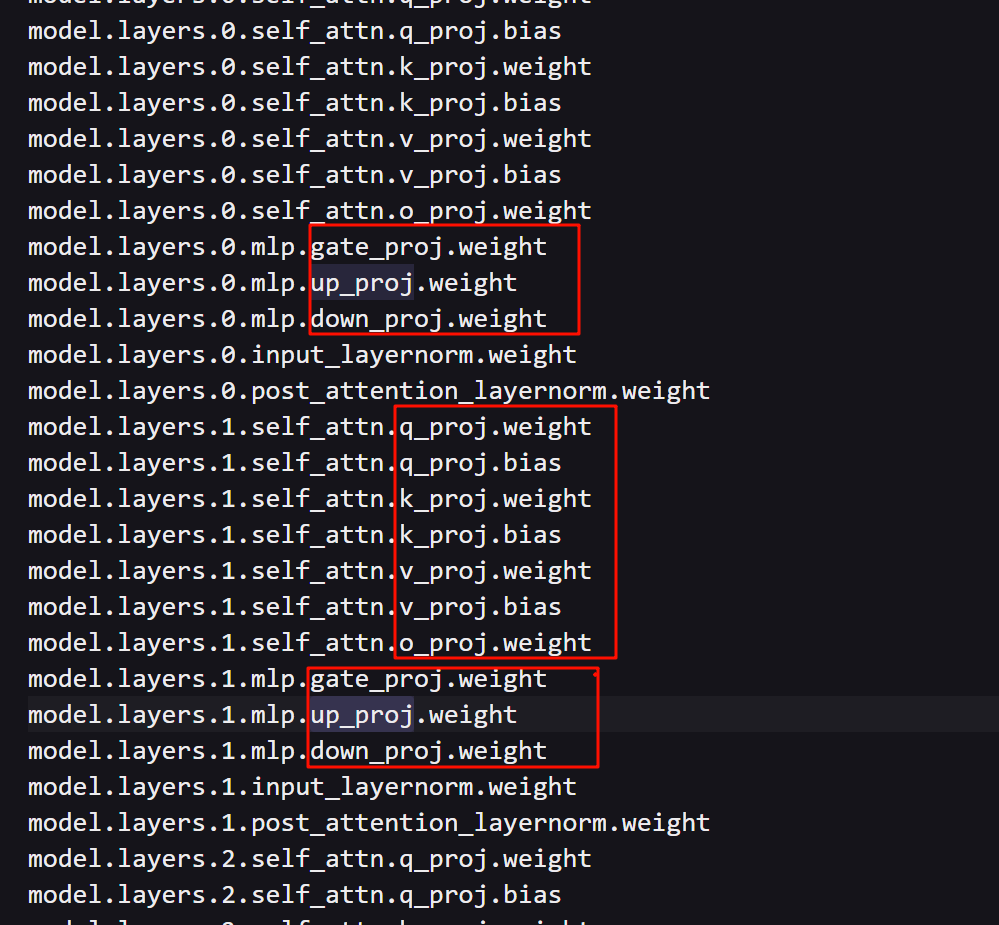
6.2 提示:特殊单词需要进行微调
当加载分词器时
1 | tokenizer = AutoTokenizer.from_pretrained("Qwen2-0.5B-Instruct") |
会提示
1 | Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained. |
这表明模型中添加了特殊标记,这些标记与词汇表中的单词嵌入有关,需要进行微调或训练
这种往往也出现在一些新的大语言模型加载时出现
在针对例如bert或者bloom基础模型时,不会出现
仅仅是提示,不需要太大关注
6.3 要区别对待DatasetDict和Dataset
正如前文所述Dataset是DatasetDict的子集,后者包括了多个Dataset
例如执行以下代码
1 | dataset = load_dataset('json',data_files='alpaca_gpt4_data_zh.json') |
会提示AttributeError: 'DatasetDict' object has no attribute 'train_test_split'
原因是load_dataset函数并没有使用split='train'参数,因此dataset是返回了DatasetDict类型,因此没有train_test_split
两种解决办法
1、dataset = dataset['train'].train_test_split(test_size=0.1)
2、dataset = load_dataset('json',data_files='alpaca_gpt4_data_zh.json',split='train')
另外有一些数据集还包括了多个子集,此时这里的split参数就要对应进行调整
6.4 提示KeyError: 'qwen2'
主要原因是transformers版本小于4.37.0后,就会报错
此时需要升级transformers库,升级的命令是pip install transformers --upgrade
6.5 使用微调后推理失败
我们在使用LoRA指令微调后的模型推理时
1 | size mismatch for base_model.model.model.layers.23.self_attn.q_proj.lora_B.default.weight: copying a param with shape torch.Size([896, 8]) from checkpoint, the shape in current model is torch.Size([1536, 8]). |
报类似这种错误,有一个可能性就是我们在加载了和当初微调时不一致的基础模型
例如我们使用了1.5B的参数进行LoRA微调,而实际在推理时我们又使用了0.5B参数的模型+LoRA的增量参数进行推理
7 完整代码
1 | from transformers import AutoTokenizer,AutoModelForCausalLM,DataCollatorForSeq2Seq,Trainer,TrainingArguments |