find 不是命令是一门语言
find 不是命令,是一门语言:用”表达式树”思维一劳永逸地征服 Linux 最强大的工具
90% 的开发者用了十年 find,却始终在背参数、查手册、踩 -exec 的坑。本文带你换一个视角:find 不是一个命令,而是一门以表达式为基本单位、以语法树为组织形式的小型语言。掌握”5 类构成”(test / action / operator / global / positional)、”短路求值”和”表达式递归嵌套”这三个核心,你不再需要记任何参数 —— 因为所有复杂命令,你都能自己推导出来。这是一篇你可以一劳永逸读完、然后把 find 那一栏从书签里删掉的文章。
一、find 的本质是”表达式”
所有的 find 命令,无一例外都遵循下面这个固定顺序的公式:
📖 官方术语对照:在 GNU find 的 man page 里,
EXPRESSION章节把表达式构成分为 5 类 —— Tests(测试)、Actions(动作)、Operators(运算符)、Global Options、Positional Options。本文为了易懂,把前两类作为主线讲解;后面提到的”选项”对应 Options,”逻辑运算符”对应 Operators。
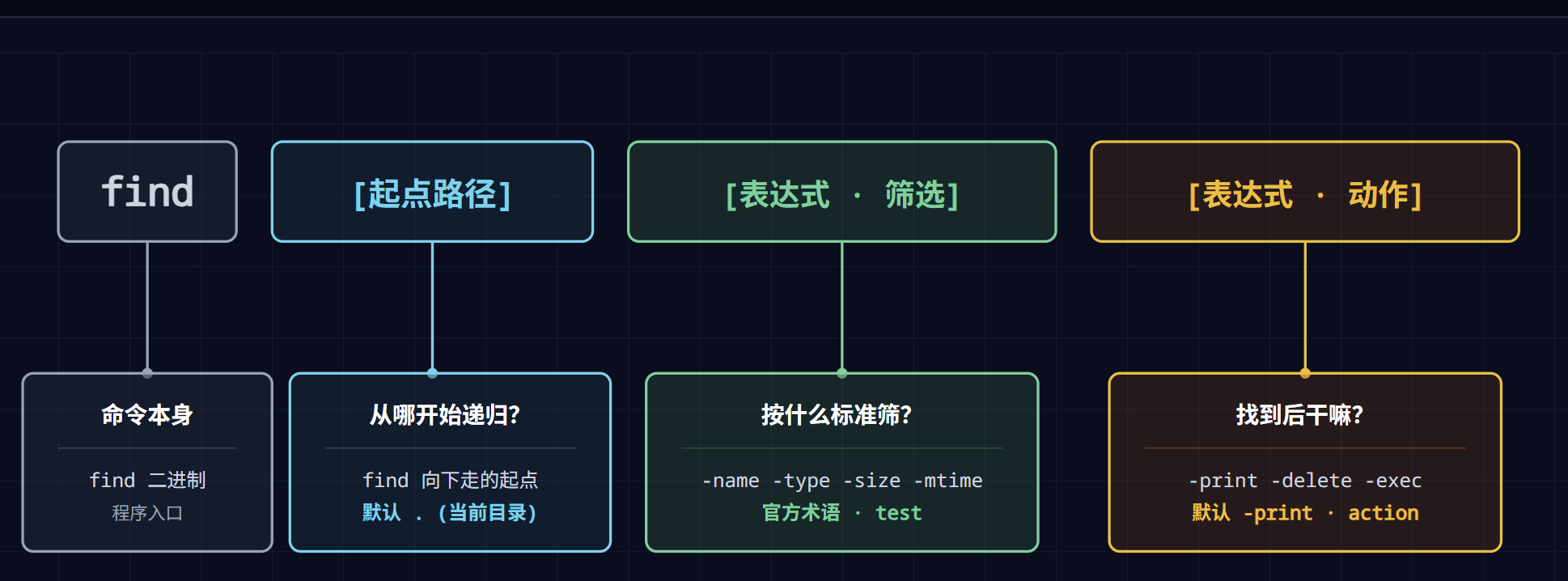
忘掉所有花哨的语法。先记住这一句:
find 遍历文件系统,对每个文件,把你写的命令从左到右执行一遍。
举个最简单的例子:
1 | find / -name "*.txt" |
find 走到每个文件,问:这个文件名字匹配 \*.txt 吗?
- 是 → 打印它(默认行为)
- 否 → 不打印
就这么简单。
多个条件怎么组合?
稍微复杂一点的例子:
1 | find / -type f -name "*.txt" -size +1M |
find 走到每个文件,依次问三个问题:
- 是普通文件吗?
- 名字匹配
*.txt吗? - 大小大于 1M?
三个都”是” → 打印;任何一个”否” → 跳过。
为什么是”都满足”?因为 find 有个隐式规则:两个条件中间什么都不写,默认就是 AND。
上面这条命令完全等价于:
1 | find / -type f -a -name "*.txt" -a -size +1M |
这里有个关键认知:
-type f、-name "*.txt"、-size +1M,每一个单独都是一个表达式;- 用 AND 把它们连起来,整体还是一个表达式。
表达式可以嵌套表达式 —— 这就是 find 被称为”表达式语言”的根本原因。
画成语法树:
1 | AND |
- 叶子节点:3 个最小表达式(谓词 + 参数)
- 内部节点:每个都是”左表达式 AND 右表达式”组合成的更大表达式
- 整棵树:一个完整的 find 表达式
再复杂的 find 命令,本质都是在这棵树上加叶子、换运算符而已。
二、find 表达式的 5 类构成(关键认知)
打开 man find,在 EXPRESSION 章节里,官方把表达式构成分成 5 类。记住这个分类,后面所有东西都建立在这上面:
| 类别 | 作用 | 返回值 | 典型例子 |
|---|---|---|---|
| Tests(测试) | 问一个”是/否”的问题 | true / false | -name "*.txt"、-type f、-perm -4000、-size +1M |
| Actions(动作) | 实际”做”一件事,有副作用 | true / false(多数为 true) | -print、-delete、-exec、-prune |
| Operators(运算符) | 把其他单元连接组合起来 | 看子表达式 | -a(AND)、-o(OR)、!(NOT)、( ) |
| Global Options(全局选项) | 影响整条命令的行为,位置随意 | 永远 true | -maxdepth、-mindepth、-mount/-xdev、-depth |
| Positional Options(位置选项) | 只影响它后面出现的 tests | 永远 true | -daystart、-regextype、-follow |
2.1 各类的核心特点
Tests(测试):只回答 true/false,不产生副作用。它是 find 的”过滤器”。
Actions(动作):会真的做事(打印、删除、执行命令……),而且动作执行后也会返回一个 true/false,这个返回值会参与后续的逻辑判断。比如 -exec grep -q "error" {} \; 既是动作(执行 grep),也是测试(grep 退出码决定 true/false)。
Operators(运算符):负责把 tests 和 actions 拼成更大的表达式。优先级从高到低是:( ) > ! > -a > -o。**两个表达式之间什么都不写,默认就是 -a**。
Global Options(全局选项):写在命令任何位置都生效,作用于整条命令。比如 -maxdepth 3 写在最前面还是最后面,效果一样 —— 都是限制整个搜索的深度。它永远返回 true,不参与过滤。
Positional Options(位置选项):只影响它后面出现的 tests。比如 -daystart 让后面的 -mtime 从今天 0 点开始算(而不是 24 小时前)。位置错了行为就变了,这是新手最容易忽略的一点。
一张图记住三组返回值

2.2 误区和重要认知
💡 一个小澄清:网上很多教程把这一类叫做”过滤器”或”过滤条件”,意思没错,但官方术语是 test,而 test 这个词更贴近本质。 “过滤器”是从功能角度命名 —— 它的作用是把文件筛掉; “test”是从返回值角度命名 —— 它的本质是返回一个 true/false。
为什么后者更准确?因为 find 表达式语言的整个逻辑(AND/OR 短路、-exec 既是动作又是测试、-prune 用 OR 短路实现剪枝……)全都建立在”返回值”这一层抽象上,而不是”过滤”这个表面功能上。抓住”返回值”,后面所有花活都能自己推导出来。
Global Options 和 Positional Options 因为不参与逻辑判断,后文在涉及它们的地方会单独说明(比如 -maxdepth 那一节),不混在表达式逻辑里讨论。
2.3 测试是否true或false
“找什么“→ test(过滤条件)。比如 -name "*.txt" 是”找名字是 .txt 的”
| 参数 | 含义 | 常见写法 | 怎么记 |
|---|---|---|---|
-name |
按文件名找 | -name "*.txt" |
name = 名字 |
-iname |
按文件名找(忽略大小写) | -iname "*.jpg" |
i = ignore case |
-type |
按类型找 | -type f |
type = 类型 |
-mtime |
按修改时间(天) | -mtime -7 |
m = modified |
-mmin |
按修改时间(分钟) | -mmin -30 |
min = 分钟 |
-size |
按大小找 | -size +100M |
size = 大小 |
-perm |
按权限找 | -perm 644 |
perm = permission |
-empty |
找空文件/空目录 | -empty |
empty = 空 |
关于时间
| 符号 | 含义 | 时间示例 | 大小示例 | 记忆方法 |
|---|---|---|---|---|
+ |
大于 / 更久 / 更老 | -mtime +7 |
-size +100M |
+ = 更大更老 |
- |
小于 / 更近 / 更新 | -mtime -7 |
-size -100M |
- = 更小更新 |
| 无符号 | 约等于 | -mtime 7 |
-size 100M |
刚好这个范围 |
2.4 选项分两类:Global 与 Positional
打开 man page 你会发现,”选项”在官方文档里其实是两类:
Global Options(全局选项)—— 位置随意,影响整条命令
| 选项 | 作用 |
|---|---|
-maxdepth N |
最多向下钻 N 层 |
-mindepth N |
至少从 N 层开始算(跳过浅层) |
-mount 或 -xdev |
不跨越文件系统边界(避免扫到挂载的别的盘) |
-depth |
先处理子文件,再处理父目录(深度优先后序) |
这类选项理论上写在哪都生效——-maxdepth 3 放在 -name 后面也能限制深度,只是 find 会给个 warning 提醒你”这是全局选项”。最佳实践是放在起点路径之后、第一个 test 之前,例如:
1 | find /var/log -maxdepth 3 -type f -name "*.log" |
Positional Options(位置选项)—— 只影响它后面的 tests
| 选项 | 作用 |
|---|---|
-daystart |
让后面的时间测试从今天 0 点算起(而不是 24 小时前) |
-regextype |
指定后面 -regex 用的正则方言(emacs / posix-basic / posix-extended 等) |
-follow |
跟随符号链接(已废弃,新版用命令前的 -L) |
这类选项位置敏感,因为它们的语义就是”从这里往后改变行为”。例子:
1 | # -daystart 在前:-mtime 0 = 今天 0 点之后修改的文件 |
💡 一句话区分:Global 是”全局开关”,开了就一直开;Positional 是”模式切换”,从切换点往后才生效。
2.5 Actions(动作)表达式(找到后干什么)
注意:很多人以为动作只是“最后做一下”,其实不是。
动作也是表达式的一部分,而且也有返回值
| 参数 | 作用 | 示例 | 记忆方法 |
|---|---|---|---|
-print |
打印结果 | find . -name "*.log" -print |
看 |
-delete |
删除 | find . -name "*.tmp" -delete |
删 |
-exec |
执行命令 | find . -name "*.sh" -exec chmod +x {} \; |
执行其他命令 |
2.6 隐含规则:没有动作时默认 -print
一个很重要的隐含规则:没有动作时默认 -print
如果你写:
1 | find . -type f -name "*.log" |
它通常等价于:
1 | find . -type f -name "*.log" -print |
但一旦你显式写了动作,比如:
1 | find . -type f -name "*.log" -delete |
就不会再默认打印。
三、Operators(运算符) :表达式之间用什么连接?
find 把多个参数连起来时,用的是逻辑运算符:
| 运算符 | 含义 | 默认/显式 |
|---|---|---|
| 空格(什么都不写) | AND(并且) | 默认 |
-a |
AND(并且) | 显式 |
-o |
OR(或者) | 显式 |
! 或 -not |
NOT(非) | 显式 |
重点:两个条件之间什么都不写,默认就是 AND。
1 | find / -type f -name "*.txt" |
等价于:
1 | find / -type f -a -name "*.txt" |
读作:是文件 并且 名字是 .txt。两个条件都为真才打印。
3.1 AND 和 OR 的”短路”行为(这是关键中的关键)
像所有编程语言一样,find 的逻辑运算符是短路求值的:
AND 的短路:左边是 false,右边不执行。
OR 的短路:左边是 true,右边不执行。
记住这两条。-prune 的所有”魔法”都建立在 OR 的短路行为上。
find 有个规则:**如果你整条命令里没写任何”动作”,find 自动在最后加一个 -print**。
所以这两条命令完全等价:
1 | find / -name "*.txt" |
四、权限(最容易混淆)用“点灯模型”破解
find -perm 确实是 find 里最容易混的表达式之一。最好的“敲门砖”是先别记复杂语法,先记一句话:
-perm 不是问“这个文件权限长什么样”,而是在问“这个文件的权限是否满足某种匹配关系”
核心就三种匹配关系:
| 写法 | 含义 | 记忆 |
|---|---|---|
-perm 644 |
权限刚好等于 644 | 精确匹配 |
-perm -644 |
至少包含 644 这些权限 | 全部满足 |
-perm /644 |
只要包含 644 中任意一位权限 | 任意满足 |
最方便的解释法:用“点灯模型”
把权限想成 9 盏灯:然后三种写法这样理解:
| 写法 | 点灯解释 |
|---|---|
-perm 644 |
灯必须一模一样,精确匹配 |
-perm -644 |
644 点亮的灯,目标文件也必须都亮,文件权限里必须至少包含 644 这些权限,全部匹配 |
-perm /644 |
644 点亮的灯,目标文件只要有一盏也亮,任意匹配 |
五、强大的灵魂-exec 参数
5.1 表达式关键认知
关键认知:-exec cmd args... \; 是一个完整的 primary(表达式单元),不可拆。
\;不是”装饰”,它是这个 primary 的结束符,等于告诉 find “我的参数到这里为止”;{}不是表达式,它只是-exec内部的文件名占位符;- 把
-exec ... \;当成一个整体,它就和-name "*.txt"一样,是表达式树上一个普通的叶子节点 —— 唯一的区别是这个叶子有副作用(会真的执行命令)。
5.2 性能比较
从 \; 进化到 +(解决性能问题)
这是最容易被忽视,但也最致命的性能问题
\;(逐个处理):找到 1 个文件,启动 1 个进程处理,再找 1 个,再启 1 个。如果找到 10 万个小文件,系统会瞬间 Fork 出 10 万个进程,直接把系统资源耗尽(Fork Bomb)。+(批量处理):把找到的所有文件名拼在命令后面,只启动 1 个进程处理所有文件
但是生产环境建议使用+
⚠️ + 的致命限制:
使用 + 时,{} 必须是命令的最后一个参数。因为 + 会把所有文件名追加到 {} 的位置,后面再写任何东西都会报错
1 | # 错误!+ 号要求 {} 必须在最后 |
使用xargs -0 -I参数
1 | find /src -type f -name "*.txt" -print0 | xargs -0 -I {} mv {} /dst/ |
⚠️ xargs -0 -I 的致命限制:
当你使用 -I {} 时,xargs 会丧失它最伟大的特性——批量处理(分批)。它不再把多个文件拼在一起传给命令,而是每读取到一个文件,就立刻启动一次命令
这和 find -exec \; 的性能灾难是一模一样的,系统会因为频繁创建和销毁进程而卡
六、安全三件套:-print0 + xargs -0 + sh -c “$@”
讲到这里,你已经掌握了 find 的所有核心能力。但有一类问题,单靠 find 自己解决不了 —— 当文件名里有空格、换行、引号、星号这些”危险字符”时,find 的输出怎么安全地传给下一个命令?
这一节给你一套生产环境可以用十年的标准方案。先看一个会出事的真实案例:
1 | # 看似人畜无害的一行 |
罪魁祸首是默认的分隔符是空格/换行 —— 而文件名本身就允许包含这些字符。要根治这个问题,需要三件套配合出场。
6.1 第一件套:-print0 —— 改用 null 作为分隔符
GNU 官方手册明确推荐:在脚本中处理任意文件名时,必须用 null 字节(\0)作为分隔符。原因很简单 —— null 是 Unix 文件名里唯一不被允许出现的字符,用它当分隔符,永远不会和文件名内容冲突。
-print |
-print0 |
|
|---|---|---|
| 分隔符 | \n(换行符) |
\0(null 字节) |
| 文件名含空格 | ❌ 会被错误切分 | ✅ 完美 |
| 文件名含换行 | ❌ 直接崩溃 | ✅ 完美 |
输出对比:
1 | # -print 输出 |
但光有 -print0 不够 —— 下游的命令也得”听得懂”null 分隔。
6.2 第二件套:xargs -0 —— 让接收方也用 null 解析
xargs -0 告诉 xargs:”别按空格切,按 null 切“。两件套一配对,整条管道就闭环了:
1 | # 安全删除 7 天前的日志 |
执行流程:
find -print0输出a.log\0b.log\0c.log\0...xargs -0按 null 切分,得到干净的文件名列表xargs把文件名一次性追加到rm -f后面:rm -f a.log b.log c.log ...
注意第 3 步是批量传参 —— 几千个文件,只 fork 一次 rm 进程。这就是 xargs 相比 find -exec ... \; 的最大性能优势。
6.3 但是!-I {} 会让你失去批量优势
讲到这里,新手很容易写出下面这种命令,看起来很自然:
1 | # ⚠️ 看起来对,但有严重性能问题 |
-I {} 的意思是”把每个文件名替换到 {} 的位置”。问题在于:**-I 一旦启用,xargs 就退化为”每个文件起一个进程”模式**,等价于 find 自己的 -exec ... \;:
1 | mv a.txt /dst/ ← fork 一次 |
xargs 的批量加速完全消失了。 这就是为什么 xargs -0 -I {} 是个看似优雅、实则反模式的写法。
那为什么很多人还是这么写?因为他们遇到了一个真问题:**mv 的参数顺序是 mv 源 源 源 ... 目标,目标必须在最后**。如果不用 -I 直接写:
1 | # ❌ 语法错误 |
所以表面上 -I 是为了”控制参数位置”,代价是”丢掉批量性能”。鱼和熊掌,似乎不可兼得。
这时候就该第三件套出场了。
6.4 第三件套:sh -c "$@" —— 兼得性能与灵活性的王者写法
直接看最终答案,再拆解:
1 | find /src -type f -name "*.txt" -print0 | xargs -0 sh -c 'mv "$@" /dst/' _ |
一行代码同时做到了:
✅ 批量传参(一次 fork 处理几千个文件)
✅ 参数位置灵活(目标 /dst/ 可以放在任何位置)
✅ 文件名带空格、换行也不会出错
这是怎么做到的? 关键在于 sh -c 启动了一个子 Shell,让 xargs 传过来的所有文件名变成这个子 Shell 的位置参数($1、$2、$3…)。然后 "$@" 一次性展开为全部位置参数。
来拆解每一个细节:
① sh -c '命令' —— 启动一个子 Shell
sh -c 'mv "$@" /dst/' 表示:”启动一个 sh,让它执行单引号里的命令”。
② xargs 把文件名作为位置参数传给 sh
不带 -I 时,xargs 会批量把文件名追加到 sh -c '...' 后面:
1 | sh -c 'mv "$@" /dst/' _ a.txt b.txt c.txt ... |
子 Shell 内部,所有文件名就是 $1、$2、$3 …,统一用 "$@" 引用。
③ "$@" —— 一次性展开所有文件名
"$@" 是 Shell 里”展开为所有位置参数”的特殊语法(注意必须带双引号,否则又会被空格切分)。所以:
1 | mv "$@" /dst/ |
一个 mv 命令,几千个文件,一次搞定。
④ 末尾的 _ 是什么?
这是这个写法里最容易被忽略的细节,也是新手最容易踩的坑。
sh -c '脚本' arg0 arg1 arg2 ... 的调用约定是:第一个参数会被当成 $0(脚本名),从第二个参数开始才是 $1、$2 …
如果不加 _:
1 | xargs -0 sh -c 'mv "$@" /dst/' ← 没有 _ |
加上 _:
1 | xargs -0 sh -c 'mv "$@" /dst/' _ ← 加一个无意义的 _ 占住 $0 |
_ 没有任何实际意义,只是个占位符,传统上大家用下划线,你想用 sh / bash / placeholder 都行 —— 但 _ 最简洁,已经成事实标准。
6.5 三件套总结:什么时候用什么
详见《 8.4 find 执行命令的选择》
七、重新理解 -prune:它不是”排除”,而是”不进入”
7.1 -prune 到底是干什么的?
一句话:**告诉 find “这个目录我不进去了,跳过它的所有子内容”**。
注意关键词:**”不进去”**,不是”不打印”。这是 90% 的人理解错的地方。
类比一下就懂了
想象你在做”全公司体检”,挨个办公室敲门检查:
1 | 公司/ |
你站在”技术部”门口,看到”node_modules”挂着牌子,你的选择是:
- **不用
-prune**:推门进去,把里面成千上万个文件挨个检查一遍(慢死) - 用
-prune:在门口标记”此屋跳过”,直接走到下一间办公室
-prune 就是这个”门口标记不进去”的动作。它不是过滤器(不是”把这个目录从结果里删掉”),而是控制器(控制 find 的递归行为)。
7.2 为什么必须是”三件套”?单用 -prune 不行吗?
这是整个 -prune 最烧脑的地方
先看一个直觉写法(错的)
1 | # ❌ 我想找所有 .log 文件,但跳过 node_modules |
你期望:跳过 node_modules,找出别的地方的 .log。 实际结果:几乎什么都打印不出来。为什么?
关键认知:-prune 自己返回 true
回想前面说的”所有 test/action 都有返回值”。-prune 这个动作的返回值是 true(永远是)。
所以上面那条命令的逻辑变成:
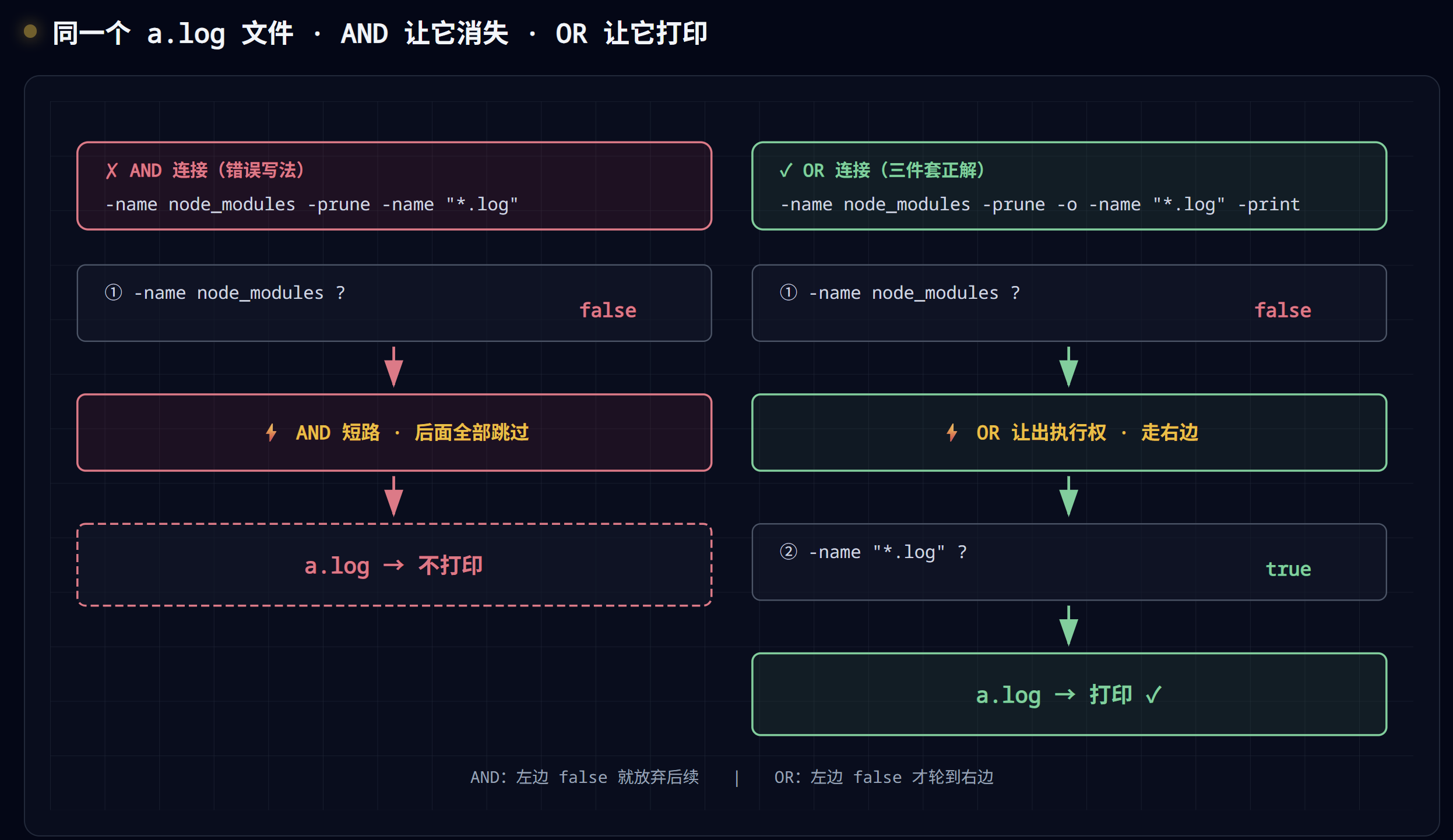
所有文件都被判为 false,所以什么都不打印。
修正:必须用 -o 把”剪枝分支”和”打印分支”分开
1 | # ✅ 正确写法(三件套) |
三件套到底是哪三件?
1 | ① -name xxx -prune ← 剪枝条件 + 剪枝动作("看到这个就别进去") |
少任何一件,逻辑都跑不通:
- 少了 ① 的
-prune:node_modules 还是会被深入扫描 - 少了 ② 的
-o:变成 AND,所有文件都被判 false - 少了 ③ 的
-print:因为前面用了动作-prune,find 的”默认 -print”被关闭了 —— 必须显式加一个-print
这就是为什么叫”三件套”:这三件像 puzzle 一样咬死在一起,少一件整体就不工作。
7.3 最容易踩两个的坑
-name 不能匹配带路径的字符串
| 想匹配的东西 | 错误写法 | 正确写法 |
|---|---|---|
名字叫 etc 的目录 |
-name /etc ❌ |
-name etc ✓ |
完整路径是 /etc |
-name /etc ❌ |
-path /etc ✓ 或 -wholename /etc |
路径里包含 node_modules |
-name */node_modules/* ❌ |
-path "*/node_modules/*" ✓ |
记法:-name 看文件名,-path 看完整路径。带 / 就用 -path
-path后续的目录不能带/
有时候系统已经提示你了,例如:
1 | find: warning: -path /etc/ will not match anything because it ends with /. |
翻译成人话:你写的 /etc/ 末尾多了一个斜杠 /,永远不可能匹配上任何东西
为什么末尾斜杠会让匹配失效?
find 遍历文件时,它给每个目录/文件生成的”路径字符串”是不带末尾斜杠的:
⚠️这样写也是错的
1 | find . -name node_modules -prune -o -name "*.log" |
跟上面正确写法的区别是:**末尾少了 -print**。
很多人觉得”find 不是有默认 -print 吗,省略一下没关系吧” —— 不行!因为:
一旦表达式里出现了会消耗默认 -print 的动作(
-delete/-exec/-printf/-ls…),默认而
-prune不在这个列表里,所以你写了-prune不会关闭默认
这条命令里没有任何”输出类动作” —— 注意 -prune 不算输出类!所以 find 会自动在最外层补默认 -print:
这就是为什么”三件套”必须显式写出 -print:哪怕你以为 find 会自动加,在这个场景下也不能依赖默认行为。
带 -print被显式 -print 消耗,不再补默认
不带 -print默认 -print 仍生效,作用于整个表达式
八、最佳实践
8.1 必须做(不做就会出事)
1. 排除目录用 -prune 三件套,三件齐全 固定模板 -name xxx -prune -o ... -print,少一件都会出怪事。
2. 处理任意文件名用 -print0 | xargs -0 文件名可能含空格、换行、引号;默认换行符分隔会让管道炸掉。
3. 路径匹配用 -path,名字匹配用 -name,带 / 必用 -path -name 只看 basename,写带斜杠的 pattern 永远返回 false。
8.2 建议做(影响性能和可读性)
4. 批量操作优先 -exec ... + 或 xargs,不用 -exec ... \; 前者一次 fork 处理几千文件,后者每个文件 fork 一次,差几十倍性能。
5. xargs 不要随便加 -I {},能不加就不加 -I 会让 xargs 退化成”每文件 fork 一次”,丢掉批量加速。
6. 参数位置不在末尾时用 sh -c '... "$@" ...' _ 王者写法 解决 mv/cp 目标必须在末尾的尴尬,同时保留批量传参的性能。
7. 用 -maxdepth N 限制深度,特别是从 / 开始搜索时 能省去 90% 无意义遍历,配合 -mount 还能避免跨挂载点扫盘。
8. 测试性删除前先用 -print 干跑一遍 把 -delete 换成 -print 看输出对不对,确认无误再换回来。
8.3 避免做(这些是反模式)
9. 不要用 ! -name xxx 排除目录 它只是”不匹配名字”,find 还是会进去扫,性能比 -prune 差 50–100 倍。
10. 不要省略 -prune 三件套末尾的 -print 默认 -print 会把被剪枝的目录名也打印出来,污染结果。
11. 不要用 -path /etc/ 这种末尾带斜杠的写法 find 看到的路径不带末尾斜杠,永远匹配不上。
12. 不要在生产脚本里依赖 find 的”默认 -print” 显式写出动作(-print / -delete / -exec),让意图清晰、行为可控。
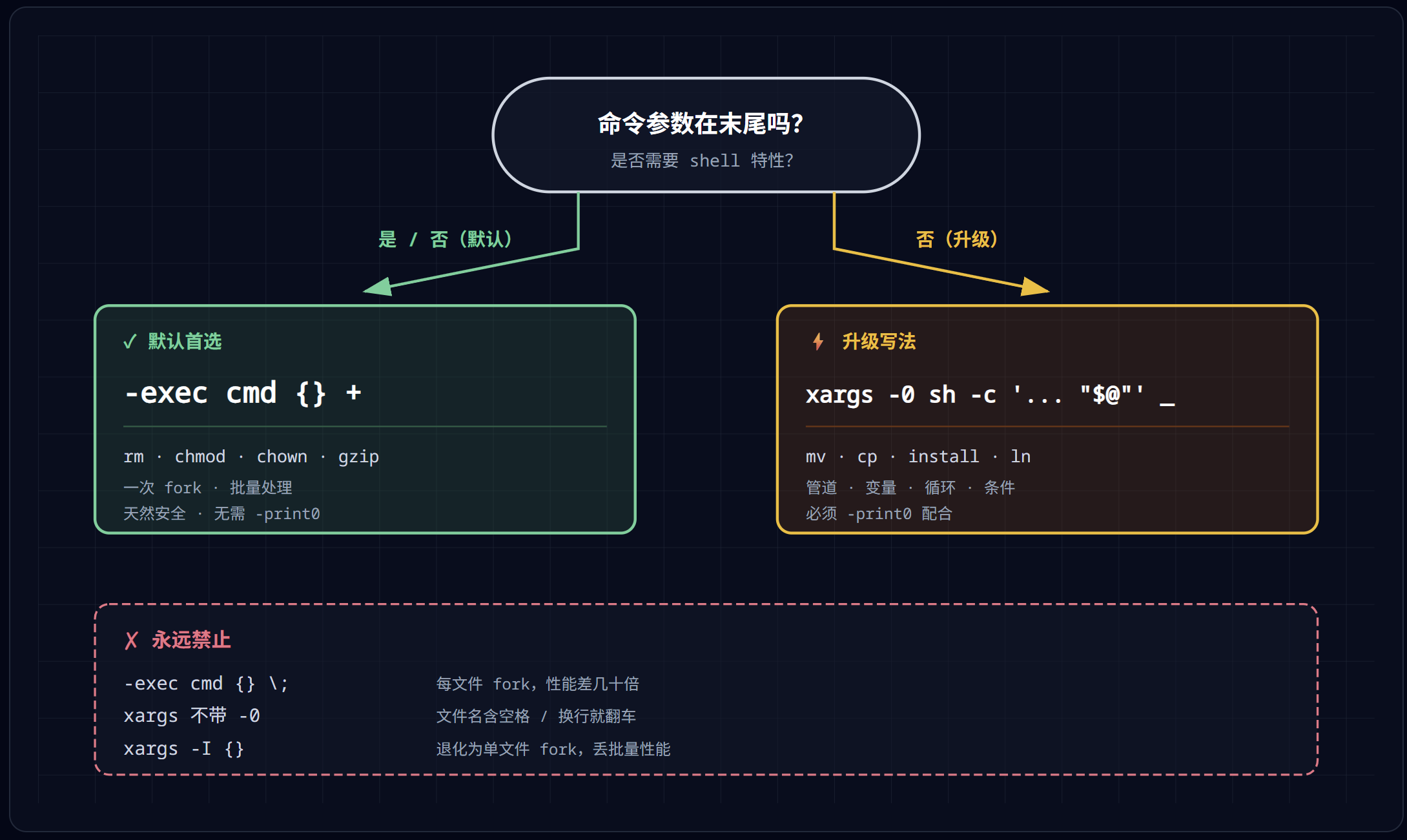
8.4 find 执行命令的选择
**默认使用 -exec cmd {} +**(带 + 的批量版)
**以下情况改用 -print0 | xargs -0 sh -c '... "$@" ...' _**:
- 命令参数位置不在末尾(mv、cp、install 等)
- 需要 shell 特性(管道、变量、循环、条件)
永远禁止:
-exec cmd {} \;(单文件 fork,性能差)xargs不带-0、find 不带-print0(文件名安全问题)xargs -I {}(退化为单文件 fork,丢失批量性能)
九、结尾:所有 find 命令都是一棵表达式树
直接看经典案例
1 | find / \( -path /var -prune \) -o \( -type f -a -name "*.log" -a -print \) |
画出来就是:
1 | OR |
任意位置都可以是测试、动作、或更小的子表达式。只要符合”运算符 + 操作数”的结构,就是合法的 find 命令。
这个视角的好处:再复杂的 find 命令,你都可以画成树拆开看,不会再被吓到
反过来理解之前所有的疑问
回顾之前几个困惑,全都是同一个根本问题的不同表现:
| 之前的问题 | 本质 |
|---|---|
“为什么要写 -o“ |
因为要把两个表达式并联起来 |
“-prune 必须在 -o 左边” |
因为 OR 短路顺序决定了”先剪枝再判断” |
| “测试和动作之间能不能用 OR” | 能,逻辑运算符不挑两边的类型 |
| “AND 和 OR 能放成对的测试+动作之间吗” | 能,因为成对的测试+动作本身就是一个表达式 |
所有问题归一:find 是一个表达式语言,里面所有东西都是”返回 true/false 的单元”,可以用逻辑运算符自由组合。