Linux 包管理进化史:每个答案,都是上一个问题逼出来的
上篇 · 包管理的诞生:从手工到自动解依赖
你大概敲过成百上千次 yum install nginx。回车,等几秒,装好了。它顺滑得像呼吸一样,以至于你从没想过去问:这中间到底发生了什么?
可一旦它出错——比如某天它告诉你”两个包在抢同一个文件,事务被中止”——你会突然发现,这个每天都在用的命令,背后藏着一套你从未真正理解的机器。你不知道它凭什么自动找到了依赖,不知道它怎么知道哪个文件归谁,不知道为什么有的软件能装两个版本、有的却水火不容。
这篇文章想带你做一件事:把这台机器拆开,但不是按零件拆,而是按时间拆。
因为 Linux 的包管理,不是某个天才一次设计出来的。它是三十年里,一代工具踩着上一代的尸体长出来的。每一个你今天觉得理所当然的功能,当年都是为了解决一个让人痛不欲生的问题才被逼出来的。而麻烦的是——每解决一个问题,几乎都会催生出一个新的、更隐蔽的问题。 正是这条”问题——答案——新问题”的链条,把包管理一步步推到了今天的模样。
读懂了这条链条,你就不再需要”背”任何命令。你会发现每一个工具的存在,都是顺理成章、甚至是不得不然的。
我们从一切的起点开始——那个还没有”包”的蛮荒时代。
一、蛮荒时代:一切靠手的混沌
最早,在 Linux 上装一个软件,是这样的:
1 | ./configure |
你下载一份源代码,自己编译,然后把编出来的文件,一个个塞进系统该去的地方。可执行文件丢进 /usr/bin,库文件丢进 /usr/lib,配置丢进 /etc,文档丢进 /usr/share/doc……
这套办法能用。但它有三个会随着时间慢慢要你命的毛病。
第一,系统失忆了。 你今天 make install 了一个软件,它把几十个文件散布到了系统各个角落。三个月后,这些文件还在,但**没有任何地方记录着”它们是谁、从哪来、属于哪个软件”**。系统对自己装了什么,一无所知。
第二,卸载是一场灾难。 正因为没有记录,当你想删掉这个软件时,你根本不知道要删哪些文件。那几十个散落各处的文件,你只能凭记忆一个个去找、去删。删漏了,留下垃圾;删错了,搞坏系统。make install 给了你安装的能力,却没给你干净撤销的能力。
第三,也是最致命的——依赖。 你想装软件 A,编译到一半,它报错:缺少 libssl。于是你去下载 libssl 的源码,编译它,结果 libssl 又说:我需要另一个库。你顺着这条线越挖越深,像在挖一口望不到底的井。等你终于把所有底层库都编译装好,几个小时已经过去了。
这三个毛病的根子,其实是同一件事:软件的”文件”和软件的”身份信息”是分离的。 系统只看到一堆散落的文件,却不知道这些文件合起来是一个有名字、有版本、有出处、有依赖关系的整体。
于是,第一个需求被逼了出来,而且无比清晰:
我们需要一个”盒子”,把一个软件的所有文件,连同它的身份信息(叫什么、什么版本、谁做的、它需要谁),整个打包在一起。安装,就是拆这个盒子;卸载,就是凭着盒子里的清单,把当初装进去的东西原样取走。
这个盒子,就是 .rpm(以及 Debian 世界的 .deb)。
二、盒子纪元:rpm,与一条悄悄立下的铁律
.rpm 文件,本质上就是上面那个”盒子”。把它拆开,里面装着三样东西:
- 文件载荷:这个软件要装进系统的所有文件,以及它们各自该去的路径。
- 元数据:这个包叫什么、什么版本、谁打的、它依赖哪些别的包、它和谁冲突、它带来的完整文件清单……
- 脚本:安装前后、卸载前后要执行的一小段代码(术语叫 scriptlet)——比如创建用户、注册服务。它在排错和安全审计时很值得留意,但不在我们这条主线上,本文不展开。
管理这些盒子的工具,就叫 rpm。
1 | rpm -i 软件.rpm # install,拆盒子装进去 |
蛮荒时代的前两个毛病,当场被治好了。
系统不再失忆——因为 rpm 在安装时,会把盒子里的元数据,完整地登记进一个本地的数据库(在 RPM 世界,它住在 /var/lib/rpm,我们后面会专门请它登场)。
从此你随时能查:这个软件装了哪些文件(rpm -ql)?这个文件到底是哪个软件带来的(rpm -qf)?这台机器上一共装了些什么?
这份登记还藏着一个常被忽略、却在安全场景里极有分量的能力:校验。既然数据库里记着每个文件原本的大小、权限、甚至内容摘要,那 rpm -V(verify)就能把磁盘上文件的现状和当初登记的”标准答案”逐一比对,告诉你哪些文件被改动过了——配置被篡改、权限被悄悄放大、二进制被替换,一查便知。
例如你运行
rpm -V curl没有返回信息,说明你的系统中curl软件包非常健康、原汁原味,不需要进行任何修复或处理。
做等保合规、做完整性核查时,这是一把内置的、几乎零成本的尺子。换句话说,这份账本不只记录”装了什么”,还默默守着”它们有没有被动过手脚”。
卸载也不再是灾难——因为有了那份登记在案的文件清单,rpm -e 能精确地知道当初装了哪些文件,原路撤销,一个不多一个不少。
到这里,请你记住一个不起眼、但将贯穿这整篇文章的设计。
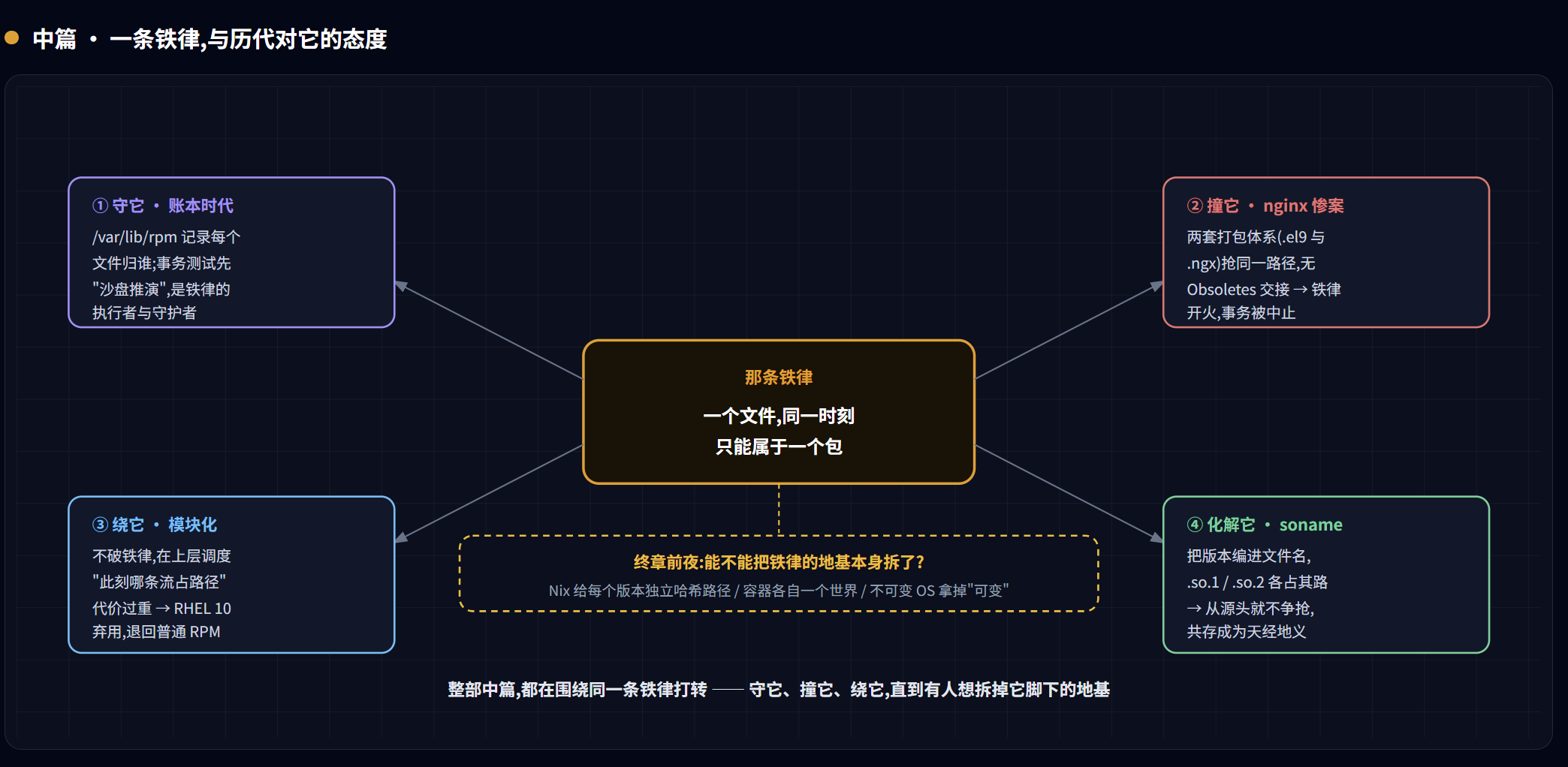
为了让”哪个文件属于哪个包”这件事不出乱子,RPM 立下了一条铁律:
系统里的任何一个文件,在同一时刻,只能属于一个包。
这条铁律此刻看起来平淡无奇,甚至理所当然,一个文件当然只能有一个主人,不然卸载的时候,删还是不删?可正是这条不起眼的规则,会在后面亲手制造出我们最棘手的麻烦,也会成为整部进化史里一次次被挑战、被绕开、最终被彻底颠覆的主角。先把它记在心里,我们继续。
盒子治好了失忆和卸载。但你有没有注意到,蛮荒时代那三个毛病里,最致命的第三个,我们还没碰?
依赖。
盒子确实把”我需要 libssl”这条信息,工工整整地写进了元数据里。可问题是——rpm 这个工具,只会读这条信息,却不会替你去做任何事。
你 rpm -i 一个需要 libssl 的包,它一看:哦,你缺 libssl。然后呢?然后它就报错、罢工、停在那里。它会忠实地告诉你”缺了什么”,但绝不会主动去帮你找来、装上。
于是你又得自己去翻 libssl 的盒子。装上 libssl,它又说还缺别的。你一个盒子一个盒子地手动追下去——这场景是不是有点眼熟?没错,蛮荒时代那口望不到底的依赖之井,又回来了。 只不过这次,井底躺的是一个个 .rpm 盒子,而不是一份份源码。
这就是无数老 Linux 用户闻之色变的四个字:
依赖地狱(Dependency Hell)。
盒子解决了”单个软件怎么装、怎么卸”,却暴露出一个它本身无力解决的新问题:软件之间是结网的,而 rpm 只会处理一个孤立的点。 它知道每个点需要连到哪些别的点,却不会自己去把这张网走通。
新的痛点,逼出了新的需求,而且同样清晰:
我们需要一个更聪明的工具。它得知道”所有可用的盒子都在哪、各自又需要谁”,然后当我说”我要装 A”时,它能自动把 A 牵连出的整张依赖网都走一遍,算出”要让 A 跑起来,总共得装哪些盒子”,然后一次性、一个不漏地装好。
这个工具,就是 yum(以及它后来的继任者 dnf)。
顺带说一句这个名字的来历,它本身就是一部微缩的传承史:YUM 是 Yellowdog Updater, Modified 的缩写。注意那个 “Modified(修改版)”——它说明 YUM 不是凭空造的,而是改写自一个更早的前身 YUP(Yellowdog UPdater),最初为 Yellow Dog Linux 而生,后来由杜克大学物理系的 Seth Vidal 等人彻底重写,用来管理他们的 Red Hat 系统。名字里就刻着一句话:我是上一代的改良版。
而为了让它能”知道所有盒子在哪”,一个全新的概念,也必须随之诞生——**仓库(repository)**。
三、大求解时代:yum,与依赖地狱的终结
要终结依赖地狱,光有一个聪明的工具还不够。它得先有”情报”——它必须知道这世上存在哪些盒子、每个盒子又需要谁。否则,再聪明的大脑,面对一片空白也无从算起。
所以 yum 的出现,其实是两个东西捆在一起登场的,缺一不可:
其一,仓库。 这是一个集中存放所有 .rpm 盒子的地方(通常是一台服务器),更关键的是,它还附带一份索引——把所有盒子的元数据(谁需要谁、谁和谁冲突)预先汇总成了一张总表。有了这张总表,工具不必把每个盒子都下载下来拆开看,只需读一遍索引,就掌握了全局的依赖关系。这就是你在 .repo 文件里配置的那些 baseurl——它们指向的,正是一个个仓库。
其二,依赖求解器(resolver)。 这才是 yum 真正的大脑。当你说”装 nginx”时,它做的事情是:从仓库索引里查到 nginx,发现它需要 A、B;再查 A,发现 A 需要 C;再查 B……它顺着这张网一路走下去,直到把所有牵连到的盒子全部找齐,在脑子里拼出一个完整的安装清单,然后才动手,一次性全部装好。
那场困扰了 Linux 用户许多年的依赖地狱,到这里,终于被终结了。 你只需要说出你想要什么,剩下那张错综复杂的依赖网,交给机器去走。
这里顺带解开一个很多人都纳闷过的现象:为什么我只 dnf install 一个小工具,它却”自作主张”地装上了一堆我没要的东西?这是因为依赖并不只有”非装不可”这一种。RPM 把依赖分了强弱:硬依赖(Requires)是”缺了就跑不起来”,必须装;而弱依赖(Recommends)是”装上体验更好、但没有也能跑”——比如某个工具推荐的插件、文档、可选后端。默认情况下,dnf 会连弱依赖一起装,让你开箱即用。那一堆”我没要的东西”,多半就是这些弱依赖。知道了这个,你就明白为什么有时想要个最精简的安装,得加上 --setopt=install_weak_deps=False 把弱依赖关掉。
这是一次巨大的解放。但我想请你停下来,看一眼这个”求解”的过程——因为这里藏着一个绝大多数人从未意识到的真相。
yum 解依赖,看起来只是”顺着箭头找下去”那么简单吗?
不是的。真实世界的依赖网,远比”A 需要 B”复杂。它充满了带版本约束的要求(A 需要 1.2 以上的 B)、互相打架的冲突(C 和 D 势不两立,不能共存)、多条可选路径(满足这个需求的包不止一个,该选哪个?)。在这样一张网里,要找出一个所有约束同时被满足、谁也不和谁矛盾的安装方案,这本质上是一道经典的计算机科学难题——约束求解,与逻辑学里的 SAT(布尔可满足性)问题同源,属于计算复杂度最高的那一类问题之一。
这不是一个煽情的比喻,而是一个被正式证明过的结论。早在 2005 年,就有研究者给出了严格的证明:软件包的安装,是一个 NP 完全问题——他们正是用 SAT 的方式,把 Debian 和 RPM 的依赖关系编码了出来。换句话说,你 install 时机器在做的事,和那些最硬核的算法难题,是同一个量级的。
换句话说:
你每一次轻描淡写的
yum install,背后其实是机器在解一道数学题。
理解了这一点,你就理解了为什么早期的 yum 有时慢得让人抓狂——它的求解算法还很原始,面对庞大复杂的依赖网,它得吭哧吭哧算很久,有时还算不出最优解。
你看,熟悉的剧情又上演了:yum 解决了”依赖要不要手动追”这个老问题,但它解决的方式(求解一道数学难题),本身又变成了一个新问题——这道题怎么解得又快又好?
这个新问题,会把我们引向下一代工具 dnf,以及它背后那个真正的”数学引擎”。
四、引擎革命:dnf,与求解的工业化
如果说 yum 第一次让机器替我们解依赖这道数学题,那么 dnf(Dandified YUM)做的事,就是把这道题交给了一个专业的解题引擎。
这个引擎叫 libsolv。
而 dnf 这个名字更是把血缘写在了脸上:它是 Dandified YUM 的缩写——“Dandified” 是”精装、翻新”的意思,而后半截直接就是 YUM。也就是说,它的全名等于明牌承认:我是 YUM 的翻新继任者。(有些文档还会俏皮地把三个字母拆成 DaNdiFied YUM,把 D、N、F 都从 Dandified 里抠出来——属于事后凑的趣味写法,不是正式词源。)
它不是 dnf 团队随手写的一段查找逻辑,而是一个独立的、专门用来求解”包依赖”这类约束问题的库——本质上,它就是一个为软件包量身定做的 SAT 求解器。还记得我们刚说的吗:解依赖,本质是解一道布尔可满足性问题。既然如此,那就请真正擅长解这类问题的算法来上场。
换上 libsolv 之后,变化是肉眼可见的:求解更快,内存占用更省,而且面对那些有多条可选路径的复杂局面,它能给出更合理的方案,而不是早期 yum 那种磕磕绊绊、有时还把自己绕进死胡同的笨办法。
所以你今天在 RHEL 9、Rocky、openEuler、Kylin 上敲的 yum,其实几乎都是 dnf 在背后干活——yum 如今多半只是一个指向 dnf 的别名,保留这个名字,只是为了照顾几代人的肌肉记忆。这本身就是进化史的一个温柔注脚:新引擎换上了,旧名字留着,谁也没察觉。
到引擎革命为止,我们似乎已经把”怎么把软件弄进系统”这件事做到极致了:盒子能装能卸,依赖能自动求解,求解还又快又准。
而且 dnf 还顺手带来了一个被严重低估的能力——时光倒流。它把每一次安装、升级、卸载都当成一笔”事务”完整地记录下来(dnf history 能看到这本流水账),更关键的是,它允许你整笔撤销:dnf history undo <ID> 能把某一次操作连根拔起(那次装了什么就卸掉、卸了什么就装回来),dnf history rollback <ID> 甚至能把系统”回退”到某次操作之后的整体状态。你 dnf update 完发现某个服务起不来了?一条 undo 就能退回去。这背后正是”事务”这个思想在撑腰——操作不是一去不回的泼水,而是可追溯、可回滚的账目。
不过它也有边界,得心里有数:内核、glibc、selinux 这类核心包的降级不在支持之列;而且一旦仓库里旧版本的包已经被删掉、找不到了,回滚就会失败——这恰恰说明,在严肃的生产环境里,留存一份带历史版本的本地源有多重要。
故事讲到这里,似乎可以圆满收场了。安装、依赖、升级、回滚——软件管理的方方面面,都被这套越来越精密的机器照顾到了。一个 Linux 管理员,似乎再没有什么可发愁的。
但请你回头看一眼,我们这一路走来,**关注的始终是同一个方向——怎么把东西”弄进来”**。从蛮荒时代手动编译,到盒子,到 yum,到 dnf,我们解决的全都是”安装”这个动作。
而真正的风暴,恰恰不在”怎么装进来”,而在”装进来之后,这台机器怎么记住这一切、又怎么守住秩序”。
有一个角色,从盒子纪元诞生那一刻起,就一直沉默地站在幕后。我们提过它一次,然后就把它搁下了。它不声不响地记着每一笔账,平时你几乎感觉不到它的存在——可一旦出事,所有的腥风血雨,主角都是它。
接下来你将看到:一条三十年来从未被打破的铁律,如何因为它而存在;一次再普通不过的 yum install,又如何因为它而当场崩盘,逼停整个系统。
那个沉默的主角,就是——数据库。

中篇 · 包管理的秩序:账本、铁律与版本共存
五、账本时代:数据库,与铁律的第一次开火
让我们把镜头拉回到盒子纪元。还记得吗?当 rpm 安装一个盒子时,它会把盒子里的元数据,登记进一台机器上的一个本地数据库(在 RPM 世界,它住在 /var/lib/rpm)。
多说一句:这份账本的底层存储格式,本身也演进过——早年用的是 Berkeley DB(你在老系统上会看到 /var/lib/rpm/Packages 这种文件),后来因为 BDB 上游维护停滞、许可证又对发行版不友好,RPM 团队把默认后端迁到了如今更稳健通用的 SQLite(/var/lib/rpm/rpmdb.sqlite)。连存放账本的”本子”本身,都在被更好的方案逼着替换——这又是一次微缩的进化。
随着系统里装的包从几个变成几百上千个,这个数据库的分量,才真正显现出来。
它是什么?它是这台机器”装了什么”的唯一真相源(single source of truth)。
但要真正讲透它,得先纠正一个几乎人人都有的模糊认识——整个包管理,其实牵着两本账,而不是一本。
一本,就是我们刚说的这个本地数据库 /var/lib/rpm,它记录”这台机器,已经装了什么“。
另一本,在远端的仓库服务器上,记录”世界上,存在哪些包“。
前者像你家的财产清单(我家里现在有哪些东西),后者像一份商品目录(商店里能买到哪些东西)。两本账记录的对象、所在的位置、服务的目的都不同,一定不能混为一谈。可偏偏它们记录的字段又长得很像,所以最容易让人糊涂。
要彻底看清它们,最好的办法就是把两本账都翻开,逐字段对照着看。
5.1 远端账本:世界上有哪些软件
我们先从远端那本”商品目录”开始,因为它的结构更直白。
你配置的每个 yum 源,服务器上都有一个 repodata/ 目录。它的入口是一个永远以明文存在的小文件 repomd.xml——你可以把它理解成”清单的清单”,里面用一条条 <data type="..."> 记录,指向真正的元数据文件在哪、校验和是多少。其中 type="primary" 那一条,指向的就是整个仓库的”商品目录”——它的真身,是一个压缩过的文件:老仓库里通常是 primary.xml.gz(gzip),较新的仓库——比如 openEuler 24.03、以及新版 createrepo_c 的默认——用的是压缩率更高的 primary.xml.zst(zstd);而 Fedora 那一脉则偏爱 primary.xml.zck(zchunk——它内部其实也是 zstd,但把文件切成了小块,好处是 dnf update 时只需下载变化的那几块,省流量)。无论哪种,解压开,里面都是一段段这样的 XML。
下面这段,就是这样一段真实的 XML——它是用 createrepo_c(把一个装满 rpm 的目录”建成 yum 仓库”的工具,会扫描所有包、生成上面说的 repodata/ 索引;你做离线内网源时几乎必用它)为一个 nginx 包生成的条目,我原样贴出来:
1 | <package type="rpm"> |
字段一目了然:名字、架构、版本(注意 epoch、ver、rel 是三个独立字段,这正是前面「大求解时代」里版本比较的依据)、校验和、它提供什么(provides)、它需要什么(requires)、它会往系统铺哪些文件(file)、以及——去哪下载它(location href)。 求解器之所以能解那道依赖数学题,靠的就是把仓库里所有包的 provides 和 requires 这两段读进来,相互匹配。
这里其实又藏着一段微缩的进化史,值得停下来看一眼。
如果你 ll 一个老仓库的 repodata/,会发现 primary 这份数据居然有两个版本并存:一个 primary.xml.gz(XML 版),一个 primary.sqlite.bz2(SQLite 版)。
为什么要存两份?因为早年 yum 嫌每次都解析 XML 太慢,于是仓库额外预生成了一份建好索引的 SQLite,让 yum 直接查、省去解析。这是典型的”用空间换时间”。可故事没完——后来 dnf 带着自己的求解库 libsolv 上场,它直接吃 XML 就够快,根本不稀罕那份预建的 sqlite。
于是新版 createrepo_c 做了个决定:默认不再生成 SQLite,只留 XML。 这就是为什么你在较新的 Fedora、RHEL、openEuler 仓库里,只剩一个 primary.xml(以 .gz/.zst/.zck 之一压缩),那个 .sqlite.bz2 不见了。
你品品:为提速而生的 SQLite 版,造出来、用了许多年,最后又被更聪明的下一代亲手淘汰,退回到只用 XML。这和我们后面会看到的”模块化兜一圈又退回普通 RPM”、以及前面”rpmdb 从 BDB 换到 SQLite”是同一种韵律——每一层优化,都在被它的下一层重新审视。
5.2 本地账本:你家的财产清单
看清了”商品目录”,现在翻开第二本账——本地这一端,/var/lib/rpm,你家的”财产清单”。
/var/lib/rpm(现在是 rpmdb.sqlite)里其实是两层东西:一层是一张张”索引表”(Packages、Basenames 等,就是前面我们扒出来的那些表名);另一层是每个包记录(Packages 表的 blob)内部、由 RPM 标签(tag)定义的几百个字段——包名、版本、文件清单这些”字段”,严格说是存在 blob 里的 RPM tag,而不是 sqlite 的列
/var/lib/rpm 为每个包记录的核心字段
| 序号 | 字段名称 | 作用 |
|---|---|---|
| 1 | Name | 包名,如 nginx。包的唯一标识主体 |
| 2 | Epoch | 纪元号,版本比较的最高优先级位(用于强制版本排序) |
| 3 | Version | 上游软件版本号,如 1.20.1 |
| 4 | Release | 发行版打包版本号,如 14.el9(同一上游版本的第几次打包) |
| 5 | Arch | 适配架构,如 x86_64、aarch64 |
| 6 | Summary / Description | 一句话简介 / 详细描述 |
| 7 | License | 软件许可证,如 BSD、GPLv2 |
| 8 | URL | 软件官方主页 |
| 9 | Vendor / Packager | 打包厂商 / 打包者信息 |
| 10 | InstallTime | 安装到本机的时间戳(财产清单独有,商品目录没有) |
一个典型的目录/var/lib/rpm/包括
1 | ll /var/lib/rpm -a |
当这个 nginx 真的装进系统后,你随时可以查它:
1 | $ rpm -qi nginx # 这个包的身份卡 |
两本账翻完,把它们对照着看,一件很有意思的事浮现出来:它们记录的字段,大体上是同一套东西——名字、版本、依赖、文件清单,几乎重合。这也正是它们容易被混淆的原因。但仔细看,有两个决定性的差异,恰好暴露了各自的使命:
- 仓库的”商品目录”里有
location(去哪下载),因为它要告诉你”世界上存在这个包,你可以来取”; - 本地的”财产清单”里有
Install Date(何时装的),以及一个商品目录永远不会有的能力——**rpm -qf反查文件归属**,因为它要记录”这台机器此刻拥有什么、每个文件归谁”。
一句话:商品目录面向”未来可能装什么”,财产清单面向”现在已经装了什么”。
你可能会冒出一个很自然的疑问:这两份数据库,是不是就对应”rpm 命令查的那份”和”dnf 命令查的那份”?
不是。 它们的分界不在”用哪个命令”,而在”在哪台机器、记录什么”:
- 本地数据库
/var/lib/rpm在你自己机器上,是全系统共用的财产清单。rpm读它(rpm -qf查归属就是在读它),dnf也读它——因为 dnf 必须先知道”系统现状”,才能算出”该装什么、会不会撞车”。 - 仓库元数据(就是那个
primary.xml,以 gz/zst/zck 之一压缩)在远端源服务器上(用到时才缓存到本地/var/cache/dnf/),主要是dnf在用。rpm这个单包工具压根不碰仓库,它只管你手里那个孤立的.rpm盒子。
所以真正的分野是:rpm 只盯着本地这一份,而 dnf 两份都握在手里。 这恰恰是 dnf 比 rpm “聪明”的根源——它一手拿着远端的”商品目录”算出该装哪些包,一手拿着本地的”财产清单”核对会不会和已装的东西冲突。

记住这句”dnf 两份都握着”。几段之后那场 nginx 惨案,正是它把两份一对照、当场撞出来的
而那个 rpm -qf——“这个文件到底归谁”——看似平平无奇,却是整个系统账本的命根子。它之所以总能给出一个确定的答案,靠的是一条从盒子纪元就埋下、并请你记在心里的铁律,从未被破坏过:
系统里的任何一个文件,在同一时刻,只能属于一个包。
现在你该明白这条铁律为什么非守不可了:如果 /usr/sbin/nginx 这个文件同时属于包 A 和包 B,那当你卸载 A 时,这个文件删还是不删?删了,B 就坏了;不删,A 就没卸干净。财产清单一旦允许”一物多主”,整个系统的账就乱了,可信度归零。所以数据库把这条铁律当成生命线来守。
它怎么守?靠的是一道在真正动手之前的安全演习。
5.3 事务:动手之前,先在沙盘上推演一遍
当你 dnf install 某个东西,求解器算出完整方案后,dnf 并不会立刻往你的磁盘上写文件。它会先做一件极其聪明的事——**事务测试(transaction test)**。
它把所有即将安装、升级、删除的包,在内存里”空跑”一遍:模拟这些文件铺到系统上之后,会不会有哪个文件撞上了已有的主人?会不会有依赖在最后一刻断裂?这就像一场实弹演习前,先在沙盘上把整个流程推演一遍,确认万无一失,才下令真正开火。
这背后,其实是一种非常深刻的工程思想——事务的原子性,也就是数据库领域常说的 ACID 里的那个 “A”:要么全部成功,要么全部不发生,绝不允许出现”装了一半”的残废状态。
dnf 对待你的系统,就像数据库对待一笔转账:宁可整笔回滚,也绝不留下一个账目不平的烂摊子。
这个设计的价值,只有在出事的那一刻才会显现。而现在,就是出事的那一刻。
5.4 铁律开火:一场真实的 nginx 惨案
让我把一个真实的事故摆在你面前。
一台 Rocky Linux 9 的机器,系统自带的官方源里,已经装了一个 nginx,版本 1.20.1。它的主程序和配置,实际是由一个叫 nginx-core 的包提供的——也就是说,/usr/sbin/nginx、/etc/nginx/nginx.conf 这些文件,此刻的合法主人是 nginx-core,这笔账清清楚楚记在数据库里。
这时,运维同学为了用上更新的特性,配置了 nginx 官方仓库,然后敲下 yum install nginx。求解器一比较版本,从官方仓库里挑中了一个高得多的版本:1.31.1,包的尾巴带着 .ngx 标记——这是 nginx 官方打包体系的印记,和系统那套 .el9(发行版官方打包)是两套互不相识的体系。
包下载好了,GPG 密钥也导入了,一切看起来都在顺利推进。然后,在最后那道事务测试里,沙盘推演发现了致命问题:
1 | Error: Transaction test error: |
翻译过来就是:那个 .ngx 的新 nginx,想把自己的主程序也放到 /usr/sbin/nginx、配置也放到 /etc/nginx/nginx.conf——可这些位置,**已经名花有主了,主人是 nginx-core**。
铁律,开火了。
这里你可能会冒出一个合理的反问:升级软件不是天天发生吗?从 nginx 1.20 升到 1.22,新版不也要占用 /usr/sbin/nginx 这个被旧版占着的路径吗?为什么平时升级不冲突,这次就撞了?
答案藏在一个 RPM 的关键机制里——**Obsoletes(废弃声明)**。
正常的同源升级,新版包的元数据里会明确写一句:”我 Obsoletes(取代)某某旧包。”这相当于一份正式的所有权交接书:RPM 一看,哦,这是合法的接班,旧包让位、新包接管那批文件,所有权平稳过户——不算冲突。这就是为什么 dnf upgrade 平时顺顺当当。
可这次的两个 nginx,来自两套互不相识的打包体系:旧的 nginx-core 是发行版官方打的(.el9),新的是 nginx 官网自己打的(.ngx)。那个 .ngx 包的元数据里,**根本没有声明”我要 Obsoletes 掉 nginx-core“**——它压根不知道 nginx-core 的存在。于是在 RPM 眼里,这不是”合法接班”,而是”两个陌生的包,同时来抢同一批文件”。没有交接书,就是硬冲突。而”一个文件只能属于一个包”这条生命线不容侵犯,于是数据库当场判定冲突,整个事务被中止。
请注意这场事故最精彩的地方:它没有造成任何损坏。
因为冲突是在”沙盘推演”阶段被发现的,真正的磁盘写入根本还没开始。系统里的 nginx 还是原来那个完好的 1.20.1,一个文件都没被动过。这正是事务原子性的胜利——
这不是”装坏了”,而是”dnf 拦住了一次会把系统装坏的操作”。它在保护你。
那个让无数人第一次见到时一头雾水的报错,本质上不是故障,而是那条贯穿三十年的铁律,在尽职尽责地守护着你系统账本的完整性。
5.5 一个连带的暗坑:你改过的配置,升级后去哪了?
既然聊到了”文件归属”,顺手揭开一个几乎每个运维都踩过、却很少有人讲清的暗坑。
想象一下:某个软件的配置文件 /etc/xxx/xxx.conf 是它的包带来的,归这个包所有。可你上线后,亲手改过这个配置(调了端口、加了参数)。现在新版本来了,新包里也带着一份它自己的、全新的 xxx.conf。问题来了:你改过的那份,和新包自带的那份,该听谁的?
RPM 的处理堪称细腻。打包者会给配置文件标记一个属性,最常见的是 %config(noreplace)——“升级时别覆盖用户改过的”。于是 RPM 这样裁决:
- 如果你没动过这个配置,直接用新版的,无声替换;
- 如果你改过,RPM 不敢擅自覆盖你的心血,于是保留你的原文件不动,把新版那份改名存成
xxx.conf.rpmnew放在旁边——意思是”这是新版的样板,你自己看着要不要合并”。 - 反过来,在某些
%config(不带 noreplace)或卸载场景下,它会把你的旧文件备份成 **xxx.conf.rpmsave**。
这就解释了那个经典困惑:**”我明明升级了,怎么新功能没生效?”**——很可能是新配置静静躺在 .rpmnew 里,而系统还在用你那份旧的。也解释了另一个反向的惊吓:”我的配置怎么被改回去了?”——也许该看看有没有 .rpmsave。养成升级后 find /etc -name '*.rpmnew' -o -name '*.rpmsave' 扫一眼的习惯,能躲掉无数玄学故障。这一切的根子,依然是那本账本在恪尽职守:它清楚每个配置文件归谁、谁动过,于是在”尊重你的修改”和”交付新版”之间,小心翼翼地两头都不得罪。
5.6 惨案背后,一个无解的新问题
事故平息了,但它留下了一个发人深省的问题。
回头看:这位运维同学其实只想做一件再正常不过的事——在同一台机器上,用上一个更新版本的 nginx。 这个诉求过分吗?一点都不。
可经典的打包模型,却结构性地做不到。原因恰恰还是那条铁律:无论 1.20 还是 1.31,它们都想占用 /usr/sbin/nginx 这同一个文件路径。而一个路径只能有一个主人。所以在经典模型里,同一个软件,同一时刻,整个系统只能存在一个版本。新旧两个版本,天生水火不容。
这在过去不是大问题。但时代变了。
如今的企业级发行版,生命周期动辄长达十年(比如 RHEL 一个大版本要维护到地老天荒)。可十年里,nginx、Python、MySQL 这些软件,早就迭代了好几个大版本。于是一个尖锐的矛盾浮出水面:
系统的底座要十年不变,以求稳定;可上面跑的应用,却需要不断用上新版本,以求先进。一个要慢,一个要快,而经典模型里”一个软件只能有一个版本”的铁律,逼着你只能二选一。
这是一个靠前面所有机制——盒子、仓库、求解器、数据库——都无法解决的新问题。它不是”怎么把包弄进来”的问题,而是一个全新的维度:怎么让同一个软件的多个大版本,在同一个系统里和平共存、还能按需切换?
要回答它,我们必须想办法绕开、甚至部分推翻那条统治了一切的铁律。
而这,正是下一段历史登场的理由。
RHEL 8 给出的回应分两层:先是一个新的仓库框架——应用流(Application Stream,即 AppStream),专门用来容纳”可以有多个版本”的上层应用;然后,为了在这个框架里真正实现”同一软件多版本共存”,它又配上了一种叫**模块化(Modularity)**的具体打包技术。
请记住这个”框架 + 实现”的分层——它是这一章结尾那个意味深长的反转的关键。
六、共存纪元:模块化,绕开铁律的第一次尝试
我们先把那个矛盾,逼到它最尖锐的形态,这样你才能体会解法的精妙。
矛盾的核心是:发行版想给你一个版本的 Python(比如 3.6),并承诺为它提供长达十年的安全维护;可你的新项目,偏偏要 Python 3.9。在经典模型里,这是死局——因为 python3 这个命令、它的库文件,路径就那么几个,两个版本一定会撞车,而铁律说一个文件只能一个主人。
那么,Red Hat 在 RHEL 8 里给出的解法是什么?
它的思路不是去打破铁律(那会动摇整个 RPM 体系的根基),而是非常聪明地绕开它。绕开的办法,是引入一个全新的概念层次,叠在经典的”包”之上。我们一层层来看。
首先,它把仓库劈成了两半。
RHEL 8 之后,你会发现系统的软件来源,分成了两个性质截然不同的仓库:
- BaseOS:操作系统的底座。内核、systemd、基础工具链……这些东西只有一个版本,稳定如磐石,十年不动。这是你脚下的地基,绝不能晃。
- AppStream(Application Stream,应用流):跑在底座上的应用软件,Python、Node.js、数据库、nginx……这里,允许多版本共存。
这个切分本身就是一个深刻的设计哲学:把”必须稳定的”和”需要灵活的”在物理上彻底分开。 nginx 日志里看到的 baseos、appstream 这两个仓库名,根源就在这里。地基归地基,应用归应用,两者不同的节奏,被装进了两个不同的盒子。
其次,在 AppStream 这个框架里,它又配上了一套具体的实现技术——“模块(Module)”和”流(Stream)”。
光把应用单独拎出来还不够,还得解决”同一个应用、多个版本”的共存问题。于是有了两个关键概念:
- 模块(Module):可以理解为”某个应用的整套打包方案”。比如
nginx是一个模块,python是一个模块。它把一个应用相关的一堆 RPM 包,捆成一个有意义的整体来管理。 - 流(Stream):这才是点睛之笔。一个模块下面,可以有多条”流”,每条流代表一个大版本线。比如 nginx 模块下面有
1.20流、1.22流;python 模块下面有3.6流、3.9流。
于是,那个原本无解的诉求,现在有了优雅的表达方式:
1 | dnf module enable nginx:1.22 # 我选 nginx 的 1.22 这条流 |
你不再是”安装某个版本的包”,而是**”在多条流里,选定一条,然后顺着它走”**。系统保证:同一个模块,同一时刻只有一条流是激活的。你想换版本,就切换到另一条流。
发现没有?铁律其实根本没有被破坏。
在任何一个确定的时刻,系统里 nginx 依然只有一个版本占用着 /usr/sbin/nginx——铁律安然无恙。模块化做的,不是让两个版本同时挤在一个路径上(那是不可能的),而是在更高的层次上,管理”此刻该让哪条流来占用这些路径”,并让切换变得干净、可控、有据可查。
这就是模块化的精髓:它没有正面推翻”一个文件只能属于一个包”那条物理铁律,而是在它之上,搭了一层”版本线的开关”。铁律管的是”此刻谁在位”,模块化管的是”该让谁上位、怎么换人”。
这是一种极高明的工程智慧:当一条底层规则无法撼动时,不要硬碰它,而是在更高的抽象层上,为它加一个调度器。
6.1 多养一本账的代价
要看清模块化到底值不值,得先知道它为了实现”共存”,在 /var/lib/rpm 这本老账本之外,额外背上了什么。它引入了两份新数据:一份在仓库侧,叫 modules.yaml(随仓库元数据下发、缓存在 /var/cache/dnf/ 下),用 YAML 定义”有哪些模块、每个模块有哪些流、每条流含哪些包、有哪些 profile 组合”;另一份在本地侧,是 /etc/dnf/modules.d/ 目录下的一堆 .module 文件,记录”这台机器为每个模块启用了哪条流”。关键的分野就在这里:老账本 /var/lib/rpm 记的是”实际装了哪个包、文件归谁”,而这两份新账记的是”我想用哪条版本线”——前者是事实,后者是偏好,分属完全不同的层。
平心而论,凭着这两份新账,模块化确实换来了三样像样的便利。其一是版本线锁定:启用 nginx:1.22 后,dnf update 只会在 1.22 这条线内部收安全补丁,绝不会擅自跳到 1.24 这样的大版本,等于自动替你挡住了”被偷偷升级”的坑。其二是整组打包切换:一句 dnf module install postgresql:13/server,就能拿到该版本配套的一整组包和预设好的安装组合,既不必自己拼凑,也不会新旧混装。其三是收窄求解:它等于告诉求解器”这软件只准在这条流里选”,让依赖结果更可预测。这些便利不能说不真实。
但把这三样便利放到天平另一头,代价立刻显得过重。多出来的 /etc/dnf/modules.d/ 这本意愿账,必须时刻和 /var/lib/rpm 这本事实账保持对齐,于是”模块流”与”普通包”裂成两套并行世界,交界处滋生出大量难以排查的故障,认知和运维成本陡增。
更要命的是,那三样好处没有一样非它不可:
锁版本,一个
versionlock插件就够;整组安装,本就有元包(meta package)能一键带全套;
收窄求解,普通用户根本无感。
模块采用的技术和朴素的”卸旧装新”没有任何区别,铁律一刻没被突破,它并没有解决任何旧机制解决不了的真问题,只是把已有的手段,换了一套更复杂、还要多养一本账的方式重新包装了一遍。
6.2 共存的秘密,全在路径上
说到这里,你心里可能升起一个尖锐的反问:既然铁律这么死板,一个路径只能一个主人,那为什么我的系统里,明明能同时躺着好几个版本的同一个库——libfoo.so.1、libfoo.so.2 安然共存,从不打架?它们不是”同一个软件的多个版本”吗,怎么就不冲突?
答案藏在一个不起眼却极聪明的设计里:soname(共享库的版本化命名)。共享库的开发者早就预见了这个矛盾,于是约定:把”主版本号”直接编进文件名。于是 libfoo.so.1 和 libfoo.so.2 从一开始就是两个不同的文件名、占着两个不同的路径——铁律压根没被触犯,它们当然能共存。需要 1.x 的老程序去链接 .so.1,需要 2.x 的新程序去链接 .so.2,各取所需,互不干扰。
这下你就看穿了一件事:为什么库能轻松多版本共存,而 nginx 那样的可执行程序却不能? 因为库从设计之初就把版本编进了文件名、主动给自己分了路径。
而 /usr/sbin/nginx 这个可执行文件的路径是写死的、不带版本的——两个版本必然抢同一个名字。
共存能不能实现,从来取决于一件事:它们占的是不是同一个路径。 soname 是”在文件名层面自己分路径”的优雅解法,模块化是”在更高层调度谁来占路径”的笨重解法,而我们后面会看到的 Nix,则是”干脆给所有东西都分配独立路径”的终极解法——殊途同归,都是在和那条铁律周旋。
6.3 但这一次,解法本身成了新的麻烦
按我们这部进化史一以贯之的剧情,你现在应该已经预感到了:模块化解决了多版本共存,但它自己,又带来了新的问题。而且这一次的问题,争议大到最后动摇了它自己的命运。
第一个麻烦是复杂度的暴涨。经典模型里,你只要想”装哪个包”。模块化之后,你得先想”启用哪个模块、激活哪条流”,再想”装哪个包”。多出来的这一层,让无数管理员栽了跟头——尤其是当模块的流和普通仓库里的包发生纠缠时,求解器会给出一些极其反直觉的结果。你或许在nginx 配置里见过的 module_hotfixes=true 吗?那行配置存在的意义,恰恰就是为了告诉 dnf:对这个第三方仓库,请绕过模块化的某些限制——它本身就是模块化带来的复杂度,逼出来的一块补丁。
第二个麻烦更微妙:模块和经典包,是两套并行的世界,它们的交界处充满了陷阱。 一个被模块”接管”的应用,和一个从普通仓库来的同名包,该听谁的?这种边界上的模糊,带来了大量难以排查的故障。
顺带说一个和”版本控制”一脉相承的实用机制。模块化用”锁定一条流”来固定大版本,但如果你不用模块、只是单纯想钉死某个包的版本,不让它被 dnf update 偷偷升级,有一个更直接的工具:versionlock。装上 dnf-plugin-versionlock,一句 dnf versionlock add nginx,就给这个包上了把锁——之后任何升级都会绕开它,直到你亲手解锁。这是把”我不要这次升级”的意愿,从”每次小心翼翼”变成”一次声明、长期生效”。生产环境里那些”绝不能动”的关键组件,值得用它焊死。
这些麻烦累积到什么程度呢?程度是:Red Hat 最终亲手把这套机制送进了历史。 而且退得干净利落、有明确的时间表——从 RHEL 9 开始,官方就逐步停止创建新模块;到了 RHEL 10,模块化作为一种打包技术被彻底放弃,官方文档的措辞不留余地:RHEL 10 不再分发任何模块化内容。
那么,多版本共存的需求消失了吗?并没有。这里要特别说清一件事,否则容易误解:被放弃的,只是”模块化”这一种实现技术,而不是 AppStream 这个框架。 AppStream 活得好好的,RHEL 10 里它依然是那个容纳上层应用的仓库——变的只是它”内部怎么提供多版本”。
那么,RHEL 10 改用什么来填充这个框架了呢?Red Hat 给出的答案,说出来你可能会愣一下——回归”带版本号的普通 RPM 包”,直接用 dnf install 安装。 也就是说,框架(AppStream)留下了,但它最初那套精巧的内部实现(模块、流),兜了整整一大圈,最后被官方亲口判定:太复杂、太难维护、得不偿失,我们还是回到最朴素的老办法吧。
请你品一品这个结局。模块化——一个曾被寄予厚望、作为 RHEL 8 旗舰特性隆重推出的实现技术,不到两个大版本,就被它的创造者判定为”不值得”,然后亲手拆掉,让那个它本想服务的框架,改回用最朴素的方式运转。这在软件史上并不常见,却也最诚实。它把这部进化史的灵魂,赤裸裸地摆在了你面前:
没有任何一个解法是终点。每一个答案,都只是”在当时的约束下所能找到的最不坏的那个”;而它带来的新问题,终将催生下一次进化——哪怕那次进化,是退回到起点。
那么,有没有一种更彻底的思路?一种不在那条铁律之上修修补补,而是从根上让”一个路径一个主人”这个前提本身不再成立的办法?
如果连”所有软件都共享同一个 /usr“这个延续了三十年的大前提,都可以被推翻呢?
这,就是我们这部进化史最后,也是最激进的一跳。
七、终章前夜:那条铁律,能不能从根上被废掉?
让我们做一次彻底的回溯。
从蛮荒时代到模块化,这一路所有的进化,无论看起来多么不同,其实都站在同一块地基上——这块地基,我们从盒子纪元起就反复在敲打:
所有软件,共享同一个文件系统;系统里的每一个路径,同一时刻只能有一个主人。
/usr/sbin/nginx 只有一个,/etc/nginx/nginx.conf 只有一个。rpm 的卸载、dnf 的求解、数据库的账本、事务测试的冲突检查、乃至模块化那套精巧的”版本线开关”——全部,都是在这块”共享的、可变的、全局唯一的文件系统”之上做文章。它们或修补、或调度、或绕行,但从没有一个,敢去动这块地基本身。
那么,一个近乎异端的问题浮现了:
如果这块地基,本身就是错的呢?
如果”一个路径一个主人”这件事,根本不必成立呢?如果可以让 nginx 1.20 和 1.31 真正地、物理地同时存在于系统里,谁也不挤占谁的路径呢?
那样的话,前面三十年里所有的痛苦——依赖冲突、版本互斥、升级把配置覆盖、装坏了难回滚——会不会有相当一部分,从根上就不存在了?
这不是空想。已经有人这么干了,而且给出了好几种截然不同的答案。它们共同构成了包管理进化史当下最前沿、也最激动人心的一跳。我们不展开细节(那足够再写一整篇),只看它们各自是怎么对那条铁律下手的:
第一种思路:让每个包住进自己的地址,从此不再有”同一个路径”。 这是 Nix 与 Guix 的世界。它们彻底抛弃了”软件都装进 /usr“的传统,转而给每一个包、每一个版本,都分配一个由内容哈希决定的、独一无二的安装路径。nginx 1.20 住在它自己的哈希目录里,1.31 住在另一个——它们从不共享任何路径,于是”一个路径一个主人”这条铁律,在这里直接失去了用武之地:根本不存在需要争夺的公共路径。版本共存不再是需要精巧调度的难题,而是天经地义的默认状态。代价是:整套思维方式都要重建,学习曲线陡峭。
第二种思路:干脆给每个应用发一个独立的世界。 这是容器(Docker 那一脉)的答案。它不去解决”如何在一个系统里共存”,而是反问:为什么非要挤在一个系统里?给每个应用打包一个自带依赖的、隔离的运行环境,让它在自己的小世界里独享一套文件系统。铁律依然在每个容器内部成立,但容器与容器之间,老死不相往来——冲突自然也就无从谈起。
第三种思路:把整个系统冻成一块只读的铁板。 这是不可变操作系统(immutable OS)的方向。它釜底抽薪地拿掉了铁律里最危险的那个词——“可变”。既然”共享可变全局态”是万恶之源,那就让系统盘只读,更新时不再是”在原地改改补补”,而是整体地、原子地换上一个新镜像,要回滚就整体换回旧的。系统状态从此干净、可预测、可复现。
你看出这三种思路的共同点了吗?它们不再像前辈那样,小心翼翼地在铁律之上修补、调度、绕行。它们做的是更狠的事——把铁律赖以成立的那个前提(“共享的、可变的、全局唯一的文件系统”)本身,给拆了。
这是三十年来,这部进化史第一次,把矛头指向了它自己的地基。
八、尾声:进化没有终点
我们从一句最朴素的 make install 出发,走到了今天。
回望整条路,你会发现它惊人地遵循着同一种韵律:手工编译的混沌,逼出了盒子;盒子的孤立,逼出了仓库与求解;求解的迟钝,逼出了更强的引擎;而要管好这一切,逼出了账本与那条铁律;铁律带来的版本死锁,逼出了模块化;模块化的复杂,又让那套实现退回原点;直到今天,有人开始追问——能不能把铁律的地基本身换掉。
每一个答案,都精确地长在上一个问题的伤口上。没有一步是凭空设计的,每一步都是被前一步的疼痛逼出来的。
所以,回到我们最初的那个问题:为什么你每天敲的那句 yum install,背后是这样一台层层叠叠、精密又笨重的机器?
因为它不是被”设计”出来的,而是被”逼”出来的。它身上每一道看似多余的褶皱——epoch 字段、事务测试、模块的流、.rpmnew 文件、那条文件归属的铁律——都是某一次真实疼痛留下的疤痕。读懂了这些疤痕,你就读懂了:你面对的从来不是一堆需要背诵的命令,而是一部仍在继续书写的、关于”如何与复杂性共处”的历史。
而它还远没有写完。Nix 会不会成为主流?容器会不会进一步吞并传统包管理?不可变 OS 会不会成为服务器的新常态?没有人知道。我们唯一能确定的是那条贯穿全文的铁律——不是”一个文件只能属于一个包”那条,而是更高的那一条:
每一个答案,都只是下一个问题的开始。
这,就是 Linux 包管理进化史;这,也是一切工程演化的宿命。
下篇 · 把模型用起来:看穿真实的坑,与一张命令地图
前两篇像一部历史剧,我们看着这套机器在一次次”问题逼出答案”中长成今天的模样。但读懂历史的真正价值,不在于谈资,而在于——当你撞上一个诡异的包管理故障时,能用脑子里的模型瞬间推演出它的根因,而不是慌乱地上网搜命令。
这一篇就来兑现这件事。我们先用前面建立的模型,去解剖几个真实世界里高频的坑,每一个都配上可以照着敲的命令;再把 rpm 和 dnf 的常用命令,按它们在模型里的”身份”重新组织成一张地图。你会发现,当你真正理解了机器,命令就不再需要死记——你只要问自己”我现在的问题属于哪一层”,答案自然浮现。
说明:下面实战里的命令都可以直接敲,但输出为节省篇幅做了精简、是示意性的,你在自己机器上跑到的具体包名和版本号会有出入——重要的是看懂”该问什么、怎么读结果”,而不是记住某一行输出。
九、用模型看穿真实世界的坑
下面每一个坑,结构都一样:先看现象,再上手诊断,然后回响前面某一章的模型点破根因,最后给解法。 你会一次次体验到那种”啊,原来文章里讲的那个机制,就是我上次踩坑的元凶”的快感。
9.1 坑一:dnf 替你做了你没要的”降级”
现象
你只想装个小工具 mytool,dnf 却在事务清单里,列出要把一个本来好好的、已装的包降级,或者给你选了一个并非最新的版本:
1 | $ dnf install mytool |
你心里一紧:我没让你动 libcommon 啊,怎么还给我降级了?
上手诊断
别急,先问清楚这些候选到底来自哪个仓库——很多时候问题就出在”源”上:
1 | # 看 mytool 和它牵连的包,各自来自哪个仓库 |
如果你发现 mytool 来自某个第三方源,而它要求的 libcommon 版本恰好和官方源里的不一致,真相就浮出来了。
根因(回响「引擎革命」的求解器模型)
还记得吗——dnf install 不是”按你说的做”,而是在所有启用的仓库的约束下,解一道数学题(SAT),找出一个它认为”全局自洽”的方案。当某个第三方源提供的 mytool 死死要求一个较低版本的 libcommon,求解器为了让”所有约束同时成立”,就只能把 libcommon 降级——这在它看来是唯一的合法解,不是 bug,是它忠实履职的结果,只是不合你意。
解法
既然根子在”多个源的约束打架”,对策就是收窄它的选择空间:用 --repo 限定这次只从可信的源里选;或者给仓库设 priority(数字越小越优先),让官方源压过第三方源;真不需要那个第三方源,就直接 dnf config-manager --disable 关掉它。一句话:当 dnf 的决定让你意外,先别怪它,去看看你给了它哪些自相矛盾的源。
9.2 坑二:改过的配置,升级后”失效”了
现象
你给某个服务改过配置(调了端口、加了参数),跑得好好的。一次例行升级之后,你发现新版的功能没生效,或者诡异的是——你改的那些参数像是”没保存”一样,服务行为又变回了默认。
上手诊断
第一反应不该是改回配置,而是先扫一眼系统里有没有”升级时被搁置的新配置”:
1 | # 揪出所有升级遗留的待处理配置 |
很可能你会看到这样的东西:
1 | /etc/myservice/myservice.conf.rpmnew |
根因(回响「账本时代」的文件归属模型)
这个 .rpmnew 就是答案。还记得吗——你改过的配置文件被 %config(noreplace) 保护着,升级时 RPM 不敢覆盖你的心血,于是保留了你的旧文件,把新版自带的那份改名成 .rpmnew 搁在旁边。所以系统此刻用的还是你那份旧配置:如果新功能需要新配置项,它自然不生效。反过来,若你看到的是 .rpmsave,则是另一种场景下你的旧文件被备份了。这一切的根子,都是那本账本在恪尽职守——它清楚每个配置归谁、谁动过,于是在”尊重你的修改”和”交付新版”之间小心翼翼。
解法
把新旧两份对比,手动合并:
1 | diff /etc/myservice/myservice.conf /etc/myservice/myservice.conf.rpmnew |
养成升级后扫一眼 .rpmnew/.rpmsave 的习惯,能躲掉无数”明明升级了却没生效”的玄学故障。
9.3 坑三:关键服务被”偷偷”升级了大版本
现象
一次再普通不过的 dnf update 之后,某个关键服务起不来了——一查,它被升级到了一个不兼容的大版本。你从没主动要求过这次大版本跳跃,它却自己发生了。
上手诊断
先回看这次到底动了什么——升级是一笔可追溯的事务:
1 | dnf history # 找到刚才那笔 update 的事务 ID |
你大概会看到 nginx 从一个保守版本,被升到了某个第三方源提供的、高得多的版本。
根因(回响「大求解时代」的版本比较 + 仓库模型)
你启用了一个提供更高版本的第三方源(典型如 nginx 官网的 mainline 主线源),而 **dnf 的天职就是”找最高版本”**。于是每次 dnf update,它都忠实地把你往那条更高的线上拽——你以为只是例行打补丁,它却顺手把大版本也换了。
解法。 既然 dnf 永远追最高版,那就明确告诉它”这个包别动”——用 versionlock 把它焊死(注意它是个插件,需先安装):
1 | dnf install python3-dnf-plugin-versionlock # 先装插件 |
万一已经被升坏了,别慌——升级是事务,可以整笔退回:
1 | dnf history undo <ID> # 撤销那笔闯祸的升级 |
(前提是旧版本的包在源里还找得到。这也是为什么严肃生产环境值得留一份带历史版本的本地源。)
9.4 坑四:两个软件,抢同一个库的不同版本
现象
你要装 app-C,dnf 报依赖冲突死活装不上:app-C 要某个库的 2.x,可系统里 app-B 正占着这个库的 1.x,两边僵住。
上手诊断——破案三连
这种”版本打架”,核心是揪出到底是谁、把版本写死成了什么。三条命令依次问下去:
1 | # 1. 先看 app-C 到底要求哪个版本 |
根因(回响「共存纪元」的 soname 模型)
还记得吗——如果一个库做了规范的 soname 版本化,libfoo.so.1 与 libfoo.so.2 各占各的路径,本可以和平共存。
所以第 3 步是分水岭:若库明明提供了两个 soname,冲突就不是库的错,而是某个包(比如 app-B)把依赖写死成了”我就要这一个具体版本号”,亲手堵死了共存的可能。
这正是”依赖地狱”在共享库层面的现代残留。
解法
看破案结果下药:如果是某个包依赖写得太死,换一个版本要求更宽松的同类包,或换打包更规范的源;如果死占旧库的是个你其实用不上的老古董(some-old-tool),评估能否直接卸掉,枷锁就解了。但如果两个都是关键业务、又真的共存不了——那就是依赖地狱的死结,这时该请出终章那一跳:别在一个系统里硬解,用容器给它们各自一个世界。
9.5 坑五:隐藏的最高位Epoch,版本号里看不见的那张王牌
前面排查升级问题时,我们一直默认”版本号大的就是新的”。但有一个隐藏字段,能凌驾于版本号之上、悄悄改写这个判断——它就是 Epoch。不认识它,你迟早会撞上一桩”版本号明明一样,dnf 却非要升级”的怪事。
先说它为什么存在。正常情况下比较版本天经地义:1.20 比 1.18 新。可总有意外——比如某个软件上游改了版本号的命名方式,新版本号在字符串比较里反而”变小”了(典型如从日期号 20231001 改成语义号 1.0,而 1.0 按位比较居然小于 20231001)。这时只看版本号,包管理器会犯傻:它认为”新版更旧”,于是死活不肯升级,甚至想给你降级。Epoch 就是为这种尴尬准备的一张王牌。
它的规则极其简单粗暴:比较两个包谁新谁旧时,先比 Epoch,Epoch 大的直接获胜,后面的版本号根本不看。 完整的比较顺序是 E-V-R 三段依次比——先 Epoch(没写默认为 0),Epoch 相同才比 Version(上游版本号),Version 还相同才比 Release(发行版打包次数,就是 .el9 前那个 -28)。Epoch 处在最高位,一票否决。所以打包者只要把新包的 Epoch 抬高一级,就等于强行宣布:”别管版本号字面大小了,我说了算,这个就是更新的。”
这套机制,正是你可能踩过的那个坑的真相。还记得在 Rocky 9 上 dnf info nginx 看到的对照吗:
1 | 已装: Epoch: 1 Version: 1.20.1 Release: 14.el9 |
注意——两个的 Version 一模一样,都是 1.20.1。如果只看版本号,它俩”一样新”,dnf 根本无从判断。可关键就在那个隐藏字段:可用版的 Epoch 是 2,已装的是 1。2 > 1,于是 dnf 一锤定音判定”可用版更新”,要把你从 Epoch 1 拉到 Epoch 2——哪怕主版本号一个字都没变。Rocky 的打包者用这一手,就是在强制声明:”我这个回移植了安全补丁的 -28 包,优先级高于任何 Epoch 1 的 nginx,请务必升上来。”
最后是它最坑人的地方:Epoch 平时是隐身的。 你 nginx-1.20.1-28.el9 这样写、这样看,完全看不到它的踪影。只有几个地方能让它现形——dnf info 里那一行 Epoch:、带冒号的完整写法 1:1.20.1-14.el9(冒号前那个数字就是 Epoch)、或者你主动去查:
bash
1 | rpm -q --qf '%{epoch}:%{version}-%{release}\n' nginx |
所以,当你遇到”两个版本号看起来一样、dnf 却坚持说有新版”这类怪事时,第一个该去看的就是 Epoch。它是版本号里那张看不见、却最大的牌——平时归零隐身,一旦打包者需要在版本号本身会误导的情况下”钦定谁更新”,它就被翻出来,一锤定音。
9.6 所以,别再无脑 dnf update 了
走完这五个场景,你或许已经回过味来:它们的肇事者,很多时候是同一个习惯——对着系统无脑敲 dnf update,然后祈祷一切安好。
很多教程会告诉你”定期 dnf update 保持系统最新就好”。这话对个人桌面无妨,但放到生产环境,它悄悄撤掉了你和系统之间最重要的一道防线。
因为一次 dnf update,可能同时引爆前面所有的坑:
它会顺着第三方源把关键服务偷偷升上不兼容的大版本(坑三);
会让一批配置悄悄变成 .rpmnew 而你浑然不觉(坑二);
会在求解时做出你没预料的降级或替换(坑一、坑四)。
而最致命的是”批量”——它一次动几十上百个包,真出了事,你几乎无法第一时间定位到底是哪一个干的。
那该怎么办?其实前面这台精密的机器,早就把工具都给你备好了:
- 升级前,先
dnf check-update看清这次要动哪些包,心里有数,而不是闭眼回车; - 关键生产组件,用
dnf versionlock焊死,把”绝不能动的”挡在 update 之外; - 把每次升级当成一笔事务:出事就
dnf history undo整笔退回(前提是本地留着旧版本); - 国产化、离线、内网场景尤其如此——用一个版本可控的本地源,有节制地升级,而不是对着公网一把梭。
说到底:无脑 dnf update 的危险,不在命令本身,而在于它撤掉了”我清楚我在改什么”这道防线。
我前面两篇讲的那台机器——事务、铁律、账本、求解器——自始至终都在保护你;但它保护的前提是,你得知道自己在让它做什么。
这,才是这五个实战真正想交给你的东西:不是五条命令,而是一种”动手前先想清楚”的态度。
而当你需要具体某条命令时,下面这张地图,随时备查。
十、一张按”模型”组织的命令地图
动手前先说明一个版本前提:下面的命令以 RHEL 8/9 的 DNF4 为基准(国产化环境如 openEuler、Kylin 多数也基于此)。RHEL 10、Fedora 41+ 改用了 DNF5,绝大多数命令照旧能用,但少数命令的子命令或旗标形态有变化——关键处我会在该条下注明。
如果你在 RHEL 10 上敲某条命令报”未知参数”,多半就是 DNF4 与 DNF5 的差异,留意对应注释即可。
最后,是这份命令清单。但请注意,它刻意不按”安装/卸载/查询”那种烂大街的分法——那种清单网上有一万份。
我们按前面建立的心智模型来组织:每一条命令,都告诉你它”住在哪一层、回答什么问题”。这样你查命令时,顺带又复习了一遍模型;而懂了模型的人,看分类就知道该用哪一类命令。
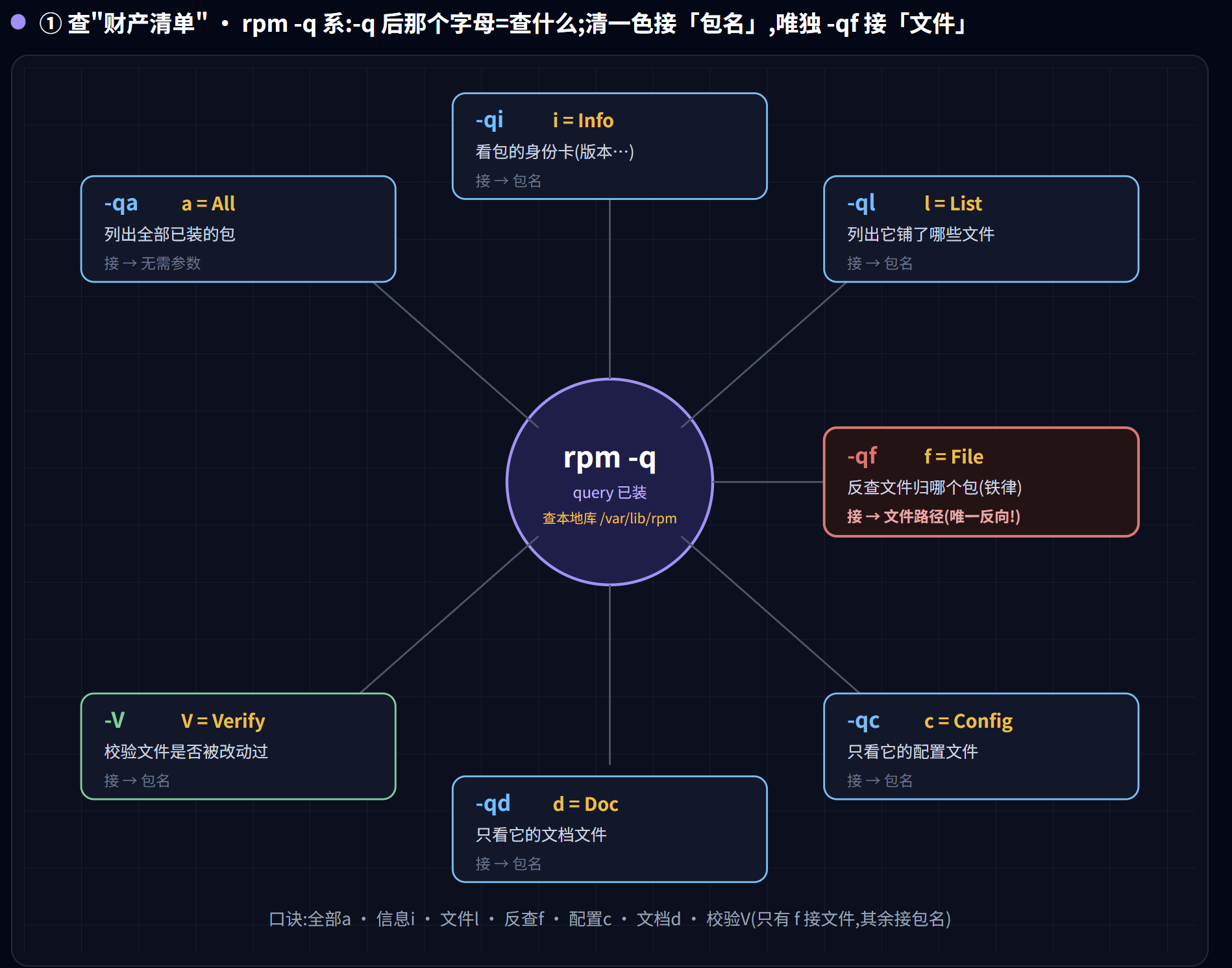
第一类 · 查”财产清单”(rpm 读本地数据库 /var/lib/rpm)
这一类全是 rpm -q(query)开头,问的都是”这台机器已经装了什么”。它们只读本地账本,不联网、不碰仓库。
rpm -qa:列出已安装的全部包rpm -qi <包>:看某个包的身份卡(版本、来源、安装时间……)rpm -ql <包>:这个包往系统铺了哪些文件rpm -qf <文件路径>:反查这个文件归哪个包所有(铁律的体现)rpm -qc <包>/rpm -qd <包>:只看它的配置文件 / 文档文件rpm -q --requires <包>/--provides <包>:它需要谁 / 它提供什么rpm -V <包>:校验文件是否被改动过(完整性核查,合规利器)
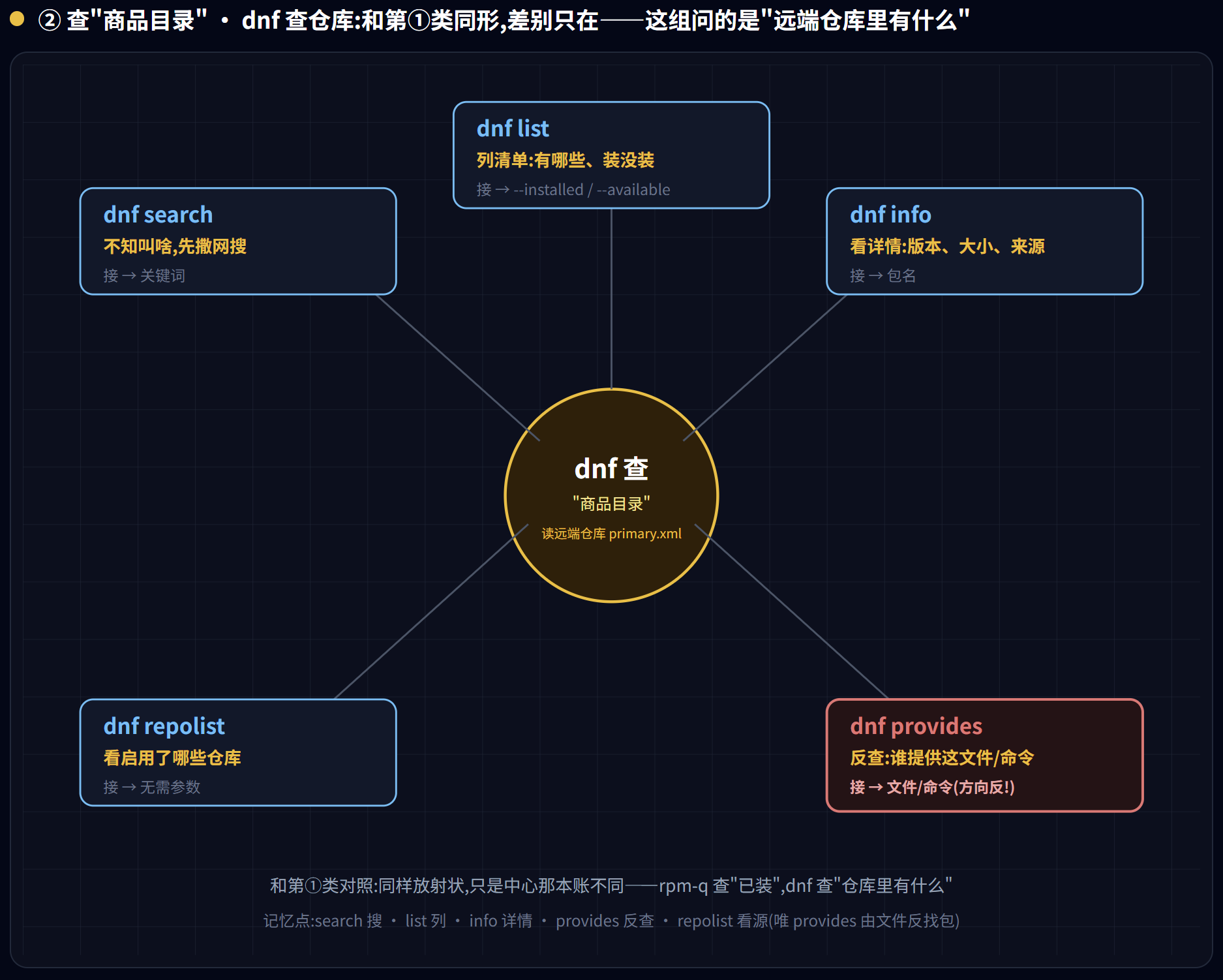
第二类 · 查”商品目录”(dnf 读远端仓库元数据)
这一类问的是”世界上存在什么、能装什么”,dnf 会去读仓库的 primary.xml。
dnf search <关键词>:按关键词搜包dnf info <包>:看仓库里某个包的详情dnf list --installed/dnf list --available:列已装的 / 可装的dnf provides <文件或命令>:”哪个包能提供这个文件/命令?”(装某个缺失命令时极有用)dnf repolist:看当前启用了哪些仓库
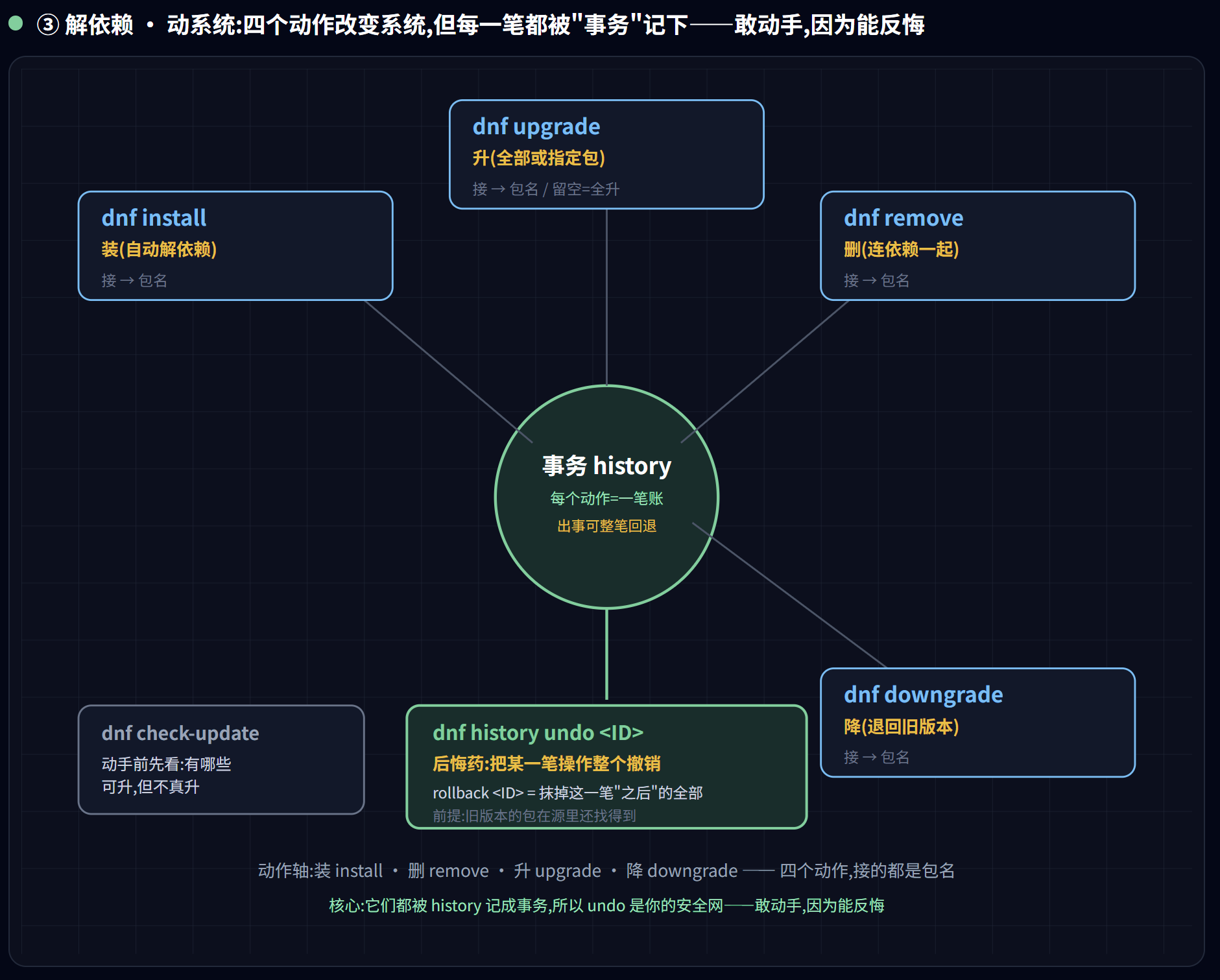
第三类 · 解依赖、动系统(dnf 求解器 + 事务)
这一类会真正改变系统状态,每一次都是一笔可追溯的”事务”。
dnf install <包>/dnf remove <包>:安装 / 卸载(自动解依赖)dnf upgrade [<包>]:升级全部或指定包dnf downgrade <包>:降级dnf check-update:只看有哪些可升级,不动手(升级前先心里有数)dnf install --setopt=install_weak_deps=False <包>:只装硬依赖,不要弱依赖(最精简安装)dnf history:查看事务流水账dnf history undo <ID>:撤销某一笔事务dnf history rollback <ID>:撤销此 ID 之后的所有事务(注意:不是”回到这一笔”,而是”抹掉这一笔以后的”)
第四类 · 管模块与流(共存纪元的遗产)
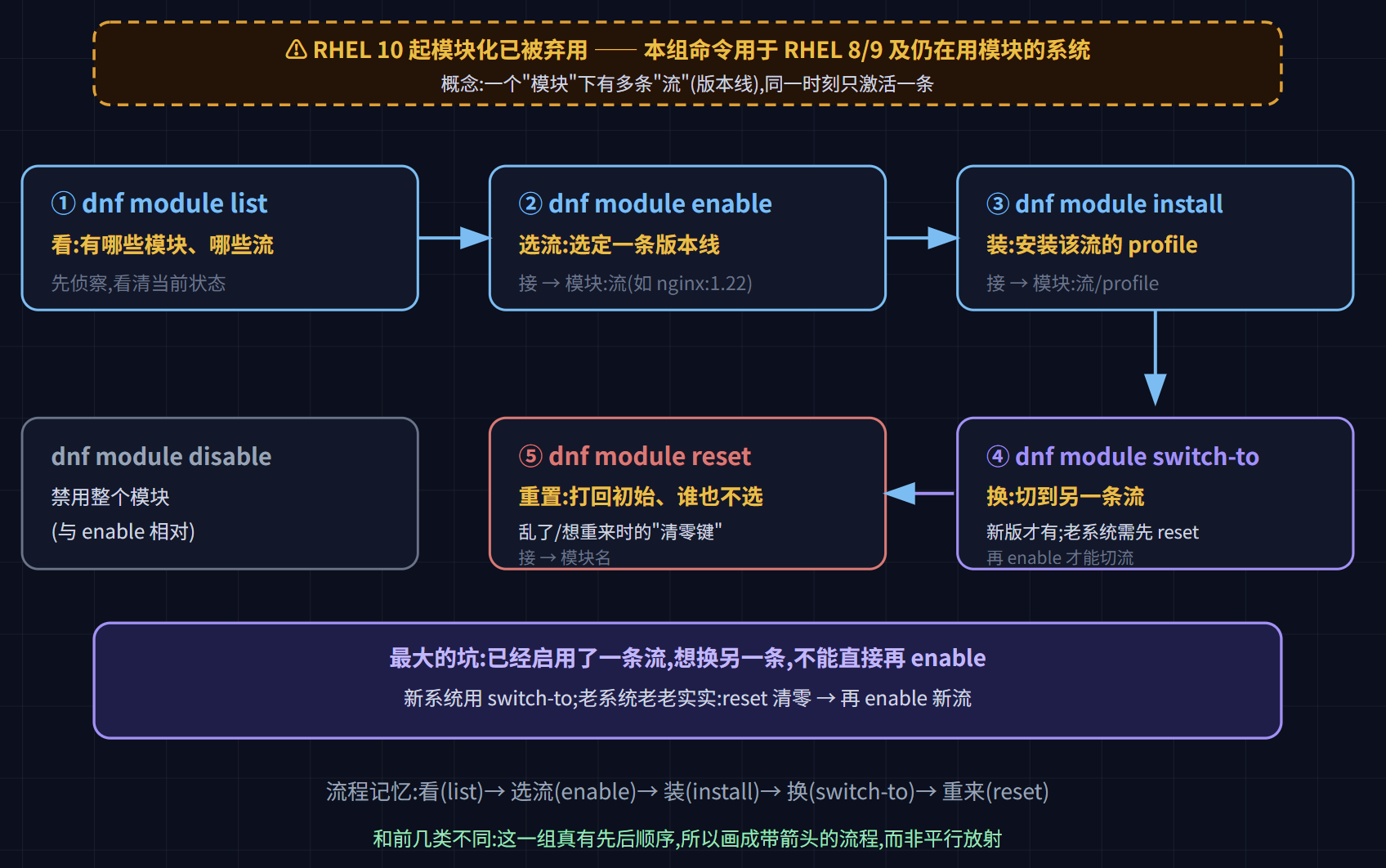
注意:RHEL 10 起模块化已被弃用,以下命令主要用于 RHEL 8/9 及仍在用模块的系统。
dnf module list:列出所有模块及其流、状态dnf module enable/disable <模块>:启用 / 禁用一个模块dnf module install <模块:流/profile>:安装某条流的某个 profilednf module switch-to <模块:流>:切换到另一条流(注意:switch-to需较新版本 dnf;老系统上切流需先dnf module reset再enable)dnf module reset <模块>:重置模块到初始状态
第五类 · 诊断与破案(把模型变成探照灯)
这一类不改变系统,专门用来”看清真相”,是上一节那些坑的解药。
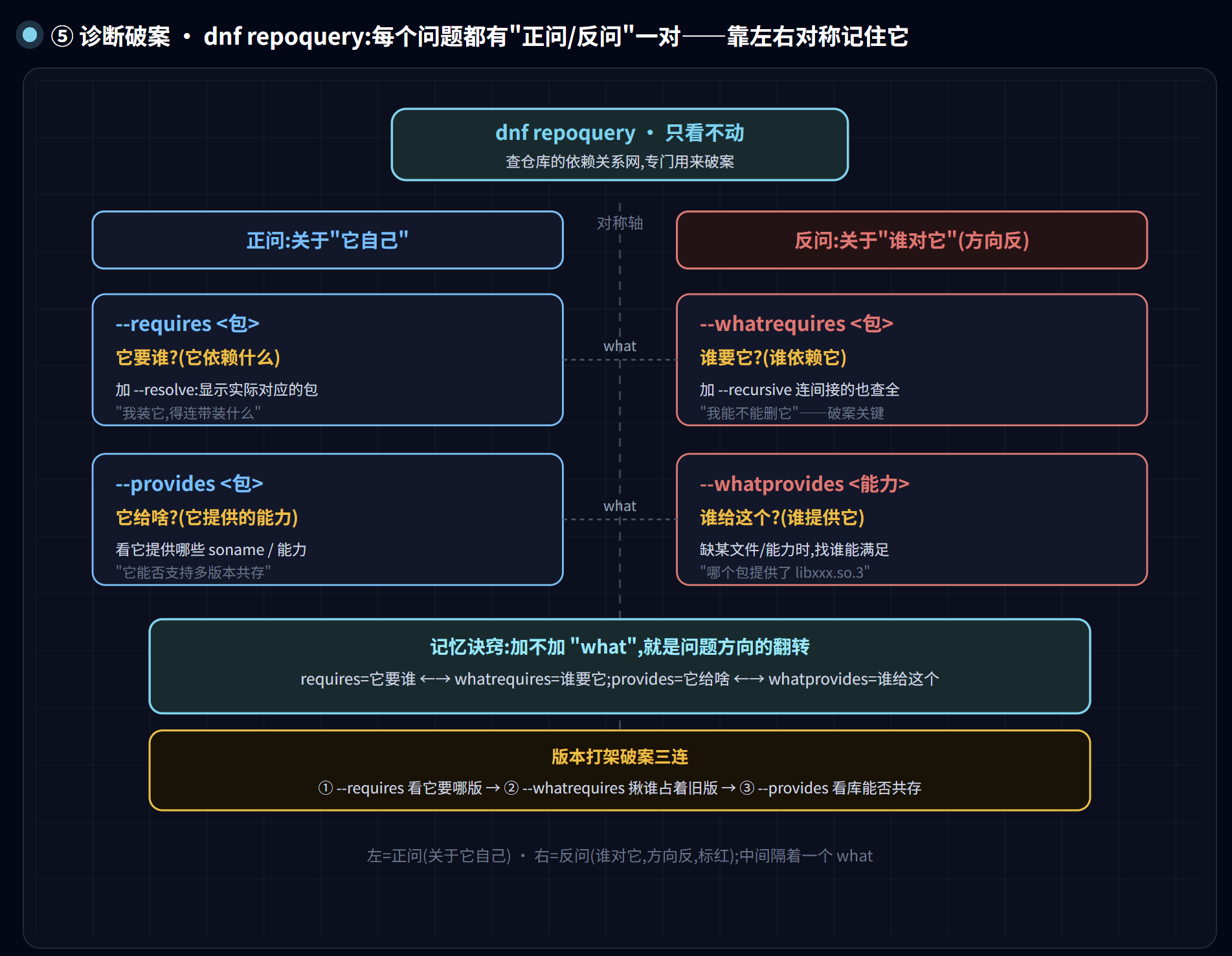
dnf repoquery --whatrequires <包>:谁依赖了它(判断能不能安全删;加--recursive连间接依赖一起查,加--installed只看已装的)dnf repoquery --requires <包> --resolve:它依赖谁(--resolve显示实际对应的包)dnf repoquery --whatprovides <能力>:谁提供了某个能力dnf repoquery --provides <包>:它提供了哪些能力 / soname(判断库能否多版本共存)dnf versionlock add/delete <包>:给包上锁 / 解锁(需先装python3-dnf-plugin-versionlock)find /etc -name '*.rpmnew' -o -name '*.rpmsave':升级后,揪出待合并的配置
第六类 · 仓库与离线源(把”商品目录”搬到本地)
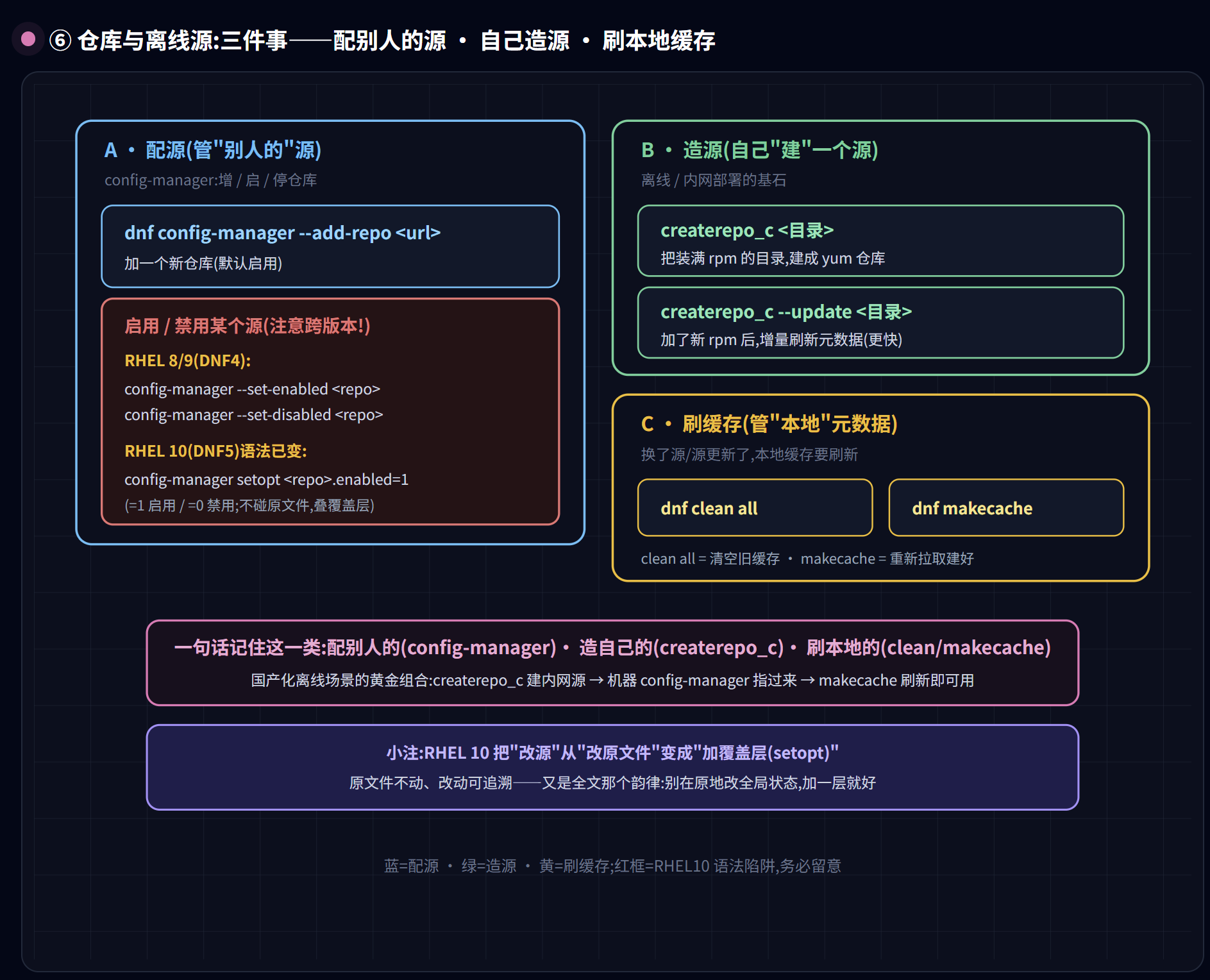
dnf config-manager --add-repo <url>:添加一个新仓库(添加后默认启用)启用 / 禁用某个已有仓库:RHEL 8/9(DNF4)用
dnf config-manager --set-enabled <repo>/--set-disabled <repo>;RHEL 10(DNF5)语法已变,改用dnf config-manager setopt <repo>.enabled=1(=1启用,=0禁用)createrepo_c <目录>:把一个装满 rpm 的目录建成仓库(离线/内网源的基石)createrepo_c --update <目录>:增量刷新仓库元数据dnf clean all/dnf makecache:清空 / 重建本地元数据缓存
为什么 RHEL 10 要改成
setopt?这不是随手换了个写法。老的
--set-enabled干的事,是跑去你的.repo文件里把enabled=0原地改成1——直接改写你的原始配置。隐患你现在应该一眼能看穿:原件被升级覆盖时改动可能丢(还记得.rpmnew那个坑吗?),而且发行版给的和你改的混在一起,分不清。DNF5 的setopt换了思路:不碰原文件,而是在专门的覆盖目录里叠加一层设置,读取时”原件 + 覆盖”叠起来生效。于是原始配置不可变、你的调整可追溯、想撤销很干净。 你品品——这跟 rpmdb 从 BDB 换 SQLite、模块化退回普通 RPM、乃至 Nix”不在原地改”是同一种韵律:软件工程在一次次教训里,越来越不肯”在原地改全局状态”,而是宁可”加一层、不碰原件”。 连改个仓库开关这种小事,都逃不过这条进化的引力。
最后请记住这张地图的用法:遇到问题,先别想”用哪个命令”,先想”我的问题属于哪一层”。
这,就是这部进化史最终想交到你手里的东西:不是一堆待背诵的命令,而是一副能看穿机器的眼睛,和一张随时可查的地图。
十一、终极复盘:敲下 dnf install 之后,到底发生了什么?
读到这里,你已经分别认识了这套机器的每一个零件:记录”装了什么”的本地账本、缓存”世界上有什么”的仓库元数据、解依赖数学题的求解器、保证安全的事务、守护文件归属的铁律。现在,是时候把它们串成一条完整的流水线了。
我们用全文的老主角做例子——dnf install nginx。当你按下回车,屏幕上不过是滚动几行进度,然后提示成功。但在这短短几秒里,七个角色按一套精密的时序协同工作了一遍。下面这张时序图,把整个过程拆成了 16 步,你可以对照着看;我把它讲成一个连贯的故事。
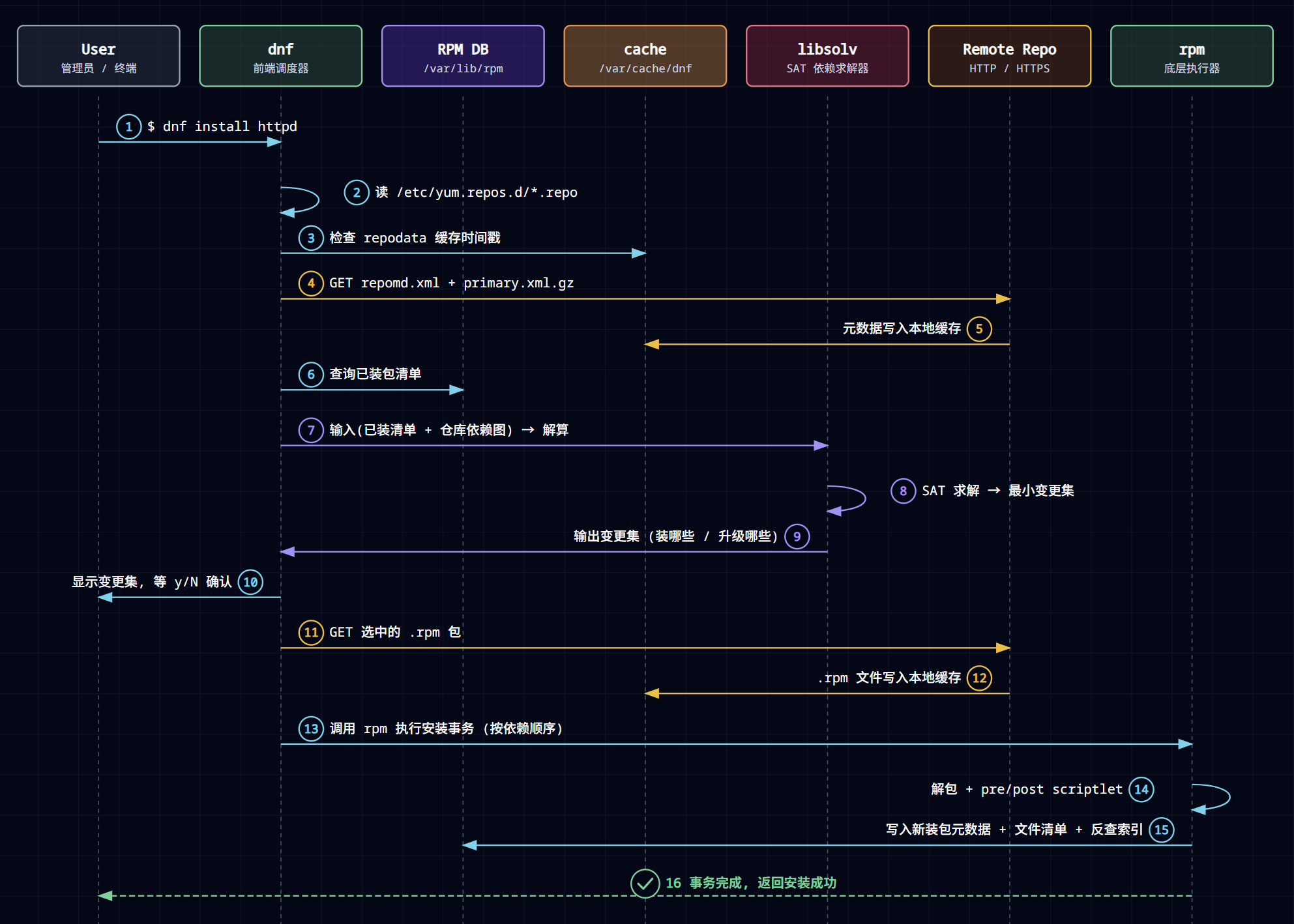
第一幕:dnf 先搞清楚”世界上有什么”(步骤 1~5)。
你敲下 dnf install nginx(步骤 1),dnf 这个前端调度器接过指挥棒。它做的第一件事不是上网,而是先读 /etc/yum.repos.d/ 下的 .repo 配置(步骤 2)——搞清楚”我手上有哪些仓库可用”。然后它去看本地缓存 /var/cache/dnf 里的仓库元数据还新不新(步骤 3):如果过期了,就向远端仓库发起 HTTP 请求,把 repomd.xml 和 primary.xml(图里画的是经典的 .gz 压缩,较新的源也可能是 .zst/.zck)这套”商品目录”拉下来(步骤 4),写进本地缓存(步骤 5)。到这里,dnf 手里就有了那本”商品目录”——世界上存在哪些包、它们彼此什么依赖关系,全在里面。
第二幕:dnf 再搞清楚”这台机器现状如何”(步骤 6)。
光知道”世界上有什么”还不够。dnf 转身查询本地数据库 /var/lib/rpm(步骤 6),把”这台机器已经装了哪些包”这本财产清单读进来。现在,它两本账都齐了——这正是前面反复强调的:dnf 比 rpm 聪明,就聪明在它一手攥着远端的商品目录,一手攥着本地的财产清单。
第三幕:把难题交给求解器(步骤 7~9)。
接下来是整台机器最烧脑的一步。dnf 把”已装清单 + 仓库依赖图”两份数据,一起喂给专业的 SAT 求解器 libsolv(步骤 7)。libsolv 在内部解这道我们讲过的、属于 NP 完全的依赖数学题(步骤 8)——在所有约束下,算出一个”全局自洽”的最小变更集:到底要装哪些、升哪些、会不会和已装的东西冲突。算完,它把这份变更清单交回给 dnf(步骤 9)。
第四幕:征求你的同意,然后下载(步骤 10~12)。
dnf 拿到变更集,不会擅自动手。它把”将要安装/升级哪些包”列出来给你看,停下来等你敲 y 确认(步骤 10)——这是你最后的刹车机会。你一旦同意,dnf 才向远端仓库下载那些选中的 .rpm 包(步骤 11),存进本地缓存 /var/cache/dnf(步骤 12)。注意:到此刻为止,你的系统还没有被改动分毫,一切都还在”准备”阶段。
第五幕:真正动手,而且全程受铁律与事务保护(步骤 13~16)。
万事俱备,dnf 把最终的执行权,交给最底层的 rpm(步骤 13)。rpm 按依赖顺序,把每个包解开、运行其中的 pre/post 安装脚本(步骤 14)——这一步如果发现要铺的文件已经名花有主,铁律就会开火、整个事务回滚(这正是那场冲突惨案的发生点)。一切顺利的话,rpm 把新装包的元数据、文件清单、以及那个让 rpm -qf 能反查归属的索引,统统写进本地数据库 /var/lib/rpm(步骤 15)——账本被更新,这台机器从此”记得”自己多了一个 nginx。 最后,成功的回执一路返回到你的终端(步骤 16),屏幕上打印出 Complete!。
回头看这一条流水线,你会发现它就是前两篇所有概念的一次集体亮相:
.repo 配置决定了”能去哪进货”;仓库元数据是”商品目录”;本地 /var/lib/rpm 是”财产清单”;libsolv 是解依赖难题的”大脑”;那句 y/N 确认背后是”事务”的审慎;rpm 落盘那一刻,既在执行铁律的检查,也在更新账本。所谓”敲一条 dnf install”,其实是这七个角色,沿着一条三十年演化出来的精密流水线,合力跑完的一场接力。 你之所以能云淡风轻地敲下回车、然后只看几行进度滚过,正是因为这套机器,已经把所有的复杂、所有的”上一个问题”,都默默替你消化在了这十六步里。