M-LAG(中·部署篇):配置顺序不是习惯,是依赖
上篇我们把 M-LAG 的心智模型焊进了脑子,一句话总结:
M-LAG 不是把两台设备合并成一台(那是堆叠),而是让两台控制平面完全独立的设备,对外”演”成一台。对外一台、对内两台;同步靠 peer-link,裁决靠 DAD。
这篇落到地面,干两件事,而且每一件都还是这句话的注脚:
- 部署 = 把这台”假的一台”按依赖顺序搭起来;
- 维护 = 让它一直演下去、别穿帮。
至于穿帮了怎么救——排障与流量的逐包推演,留给下篇。
命令基于真机环境:华为 CloudEngine CE6856-48T6Q-HI,版本为 V200R023C00SPC500。
一、部署:照着”对外一台、对内两台”的依赖顺序搭
很多人配 M-LAG 配不对,不是命令记错,是顺序没想清楚。配置顺序不是随便排的,它就是 M-LAG 各部件的依赖关系:两个独立的大脑,要先能找到对方——DFS 配对,走的就是 DAD 那条三层小路上的 source/peer IP。配对上了,才谈得上同步,peer-link 这时才有意义。同步跟得上了,才敢对外露脸,把成员口亮出来。最后补上三层网关与逃生链路,把三层的后路留好。
下面就按这条依赖链一步步配,每步配完紧跟一段验证——**配置只说明”我想让它怎样”,验证才告诉你”它真的怎样了”**。
1.0 先做规划:把”对内两台”的差异点列清楚
M-LAG 两台设备的配置绝大部分对称、少数几处必须不同。开工前先把不同点钉死,能省掉一大半排障:
| 项 | SwitchA | SwitchB | 必须 |
|---|---|---|---|
| 系统 MAC(设备本身) | 各自缺省、保持不同 | 各自缺省、保持不同 | 必须不同(相同会导致 DFS 配对失败) |
| DFS 优先级 | 150(设为主) |
120(低于 A,为备;缺省为 100) |
决定主备(华为:大者为主) |
| DAD / DFS source IP | 192.168.100.181 |
192.168.100.182 |
必须不同且互为对端(本文取带外管理地址) |
| 路由 router-id | 各自唯一 | 各自唯一 | 必须不同 |
| 桥 MAC(V-STP) | 3ce8-2452-28c0 |
3ce8-2452-28c0 |
必须相同(取两台中系统 MAC 较小的一台) |
| 网关虚拟 MAC(VLANIF) | 0000-5e00-0011 |
0000-5e00-0011 |
必须相同,每个 VLANIF 接口必须不同 |
| 网关 IP、VLAN、m-lag-id | 一致 | 一致 | 必须相同 |
网关虚拟 MAC(VLANIF)选择前缀 0000-5e00:该前缀归 IANA 所有,物理网卡不会使用,取自这里可确保不与真实 MAC 冲突;属通行惯例,非强制要求。
桥 MAC:在 M-LAG 场景下两台必须配置相同桥 MAC,可以选择其中一台设备的系统 MAC(
display system mac-address查看)作为两台共同的桥 MAC,且建议选取两台设备中 MAC 地址较小的那个。
一句话记法:凡是”对外那张脸”的属性(桥 MAC、网关 IP/MAC、m-lag-id)两台必须一模一样;凡是”设备自己是谁”的属性(系统 MAC、router-id、source IP)两台必须各不相同。 这正是”对外一台、对内两台”在配置上的投影。
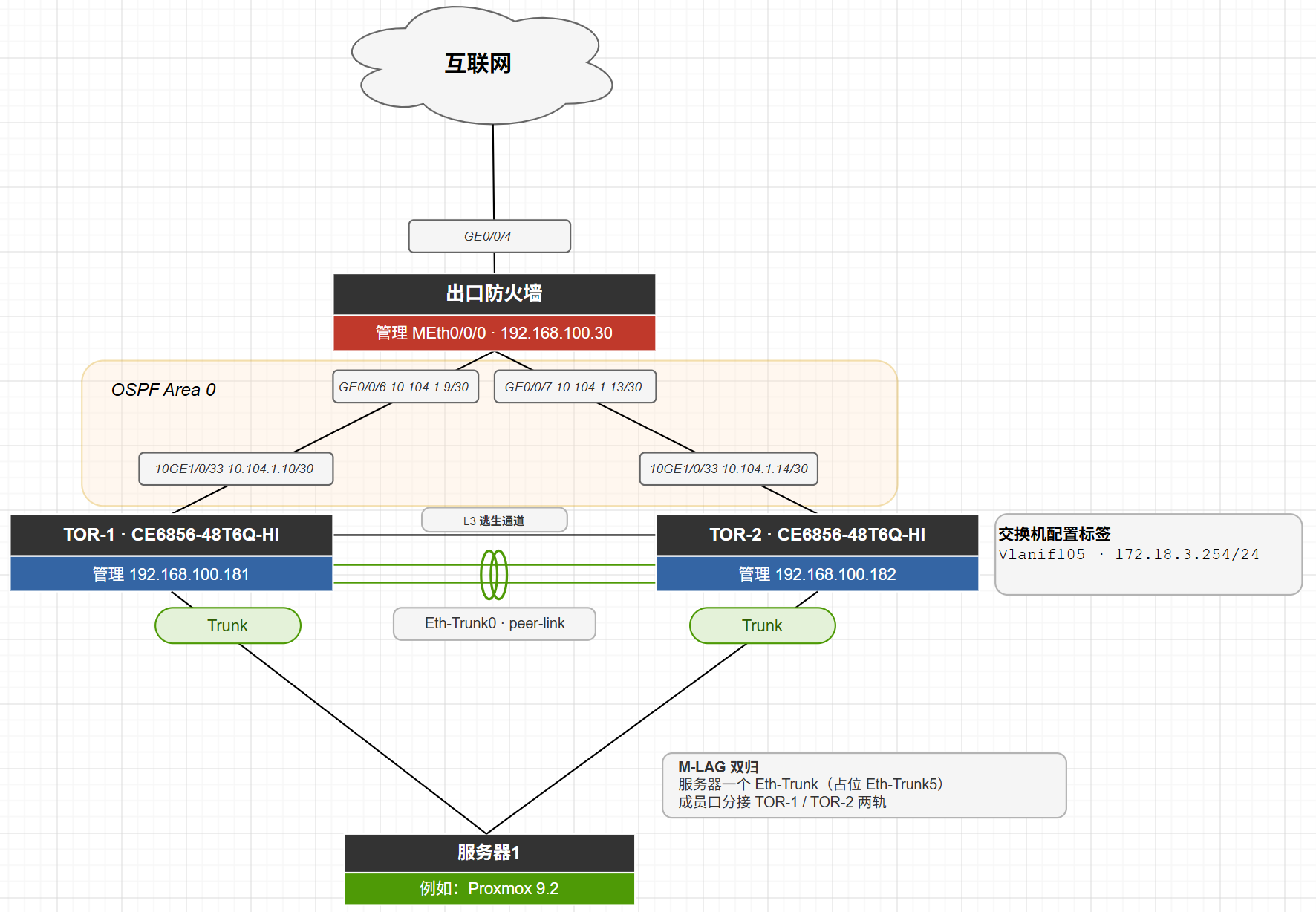
拓扑约定:peer-link 用
Eth-Trunk0(40GE×2);DAD 走带外管理口;成员口Eth-Trunk5(绑 m-lag 5,物理口 10GE1/0/5)接服务器,业务 VLAN 105,网关172.18.3.0/24;三层逃生链路用独立三层口 10GE1/0/40;上行 10GE1/0/33 各自起 OSPF 对接防火墙。
拓扑示意图参考如下:
1.1 V-STP 打底:先想清楚”为什么还要开生成树”
上篇讲过,M-LAG 内部那条潜伏环路靠单向隔离破,根本不靠 STP。那这一步为什么还要开生成树?因为单向隔离只管”M-LAG 内部”,管不了 M-LAG 之外,而 M-LAG 朝上游这一侧有两件事必须交代清楚:
- M-LAG 之外的二层网络仍可能成环。 M-LAG 通常只是整张二层网络的一部分,它上面、旁边还可能有别的交换机和冗余链路——那部分环,单向隔离够不着,得靠通用的 STP 来破。这是 STP 的本职。
- 更要命的是 M-LAG 自己怎么”参与”这棵树。 两台设备会和上游互发 BPDU、参与整网的生成树计算。如果它们以两个独立的桥身份、各算各的状态参与,STP 很可能算出”该 block 掉 M-LAG 的某个口”——轻则阻塞端口、破坏双活,重则两台状态不一致、留下环路。
所以开生成树的真正目的,不是给 M-LAG 内部破环,而是把”对外一台“这条总纲延伸到生成树平面:让两台设备用同一个桥 ID、同一份状态参与计算,对上游表现成同一个 STP 节点。否则可能存在环路风险(华为官方明确要求)。
三种实现方式:把”两台装成一个 STP 节点”的三种手法
华为给了三种组网方式,分类轴其实是两个维度的组合——**”靠什么装成一个节点”(被动占位 / 主动同步)× “网络跑的是哪种生成树方言”(STP-RSTP / 逐 VLAN 的 VBST)**:
| 根桥方式 | V-STP | V-VBST | |
|---|---|---|---|
| 手法 | 被动占位:两台都强配成根桥 + 相同桥 ID | 主动同步:经 peer-link 实时同步 STP 状态 | 主动同步,但同步的是 VBST 状态 |
| 适配协议 | STP/RSTP(且自己得是根桥) | STP/RSTP | VBST(逐 VLAN,对标思科 PVST) |
| 两台是否共享 STP 视图 | 否,各跑各的 | 是 | 是 |
| 必须处在根桥位置 | 是(命门) | 否,树里任意位置都行 | 否 |
| 多级级联 M-LAG | 不支持 | 支持 | 支持 |
- 根桥方式的巧思:既然两台都是根桥、桥 ID 又相同,根桥的端口天生都是指定口、永远不被 block,成员口自然不被阻塞。但它不交换 STP 状态,纯靠”恰好都坐在塔顶”——一旦 M-LAG 不在根桥位置(最典型就是多级级联 M-LAG,下层那对根本不是根),这招直接失效,且不支持 STP 多进程。
- V-STP才是真正”同步状态、虚拟成一个桥”:不管 M-LAG 在树里处于什么位置都能正确演成一个节点。
- V-VBST只是把同样的虚拟化思路套到逐 VLAN 生成树(VBST)上,给”现网已经在跑 VBST / 要和思科 PVST 对接”的环境用。
为什么推荐 V-STP
一句话:它”既通用又不挑位置”,根桥方式的限制它全没有,VBST 的复杂度它又不背。
- 不挑位置:主动同步状态,是不是根桥都能正确表现为一个节点;
- 多级级联只能用它:级联 M-LAG 场景根桥方式根本做不了,华为明确要求用 V-STP;
- 支持 STP 多进程(V200R002C50 及之后),根桥方式不支持;
- V-VBST 只在确实需要逐 VLAN 生成树时才用——多数数据中心普通 RSTP 就够,没必要引入 VBST 的复杂度。
所以默认走 V-STP,让两台用同一个桥 MAC 对外参与计算:
使用 display system mac-address 显示自己的系统 MAC 地址。
1 | # SwitchA 与 SwitchB 配置完全相同 |
验证:
1 | display stp v-stp |
V-STP Mode : True表示 V-STP 已生效(若为 False 说明stp v-stp enable未提交或未生效);Bridge Mac的 Config 与 Active 值应一致,备设备应同步主设备的桥 MAC。
1.2 V-STP 场景的配置顺序
在 V-STP 场景中,华为推荐按照如下顺序完成 M-LAG 的配置和物理连线:
- 配置 V-STP。
- 配置 DFS Group 和 peer-link 接口。
- 用线缆连接 M-LAG 主备设备的 peer-link 接口。
- 配置 M-LAG 成员接口,并用线缆连接 M-LAG 主备设备与用户侧主机(或交换设备)。
这个顺序的用意就一条:先配置、后连线。如果反过来——线先插上、配置再一条条敲——设备就会经历一段危险的”半成品”状态:桥 MAC 已经改成一样、peer-link 却还没通,网络里就有两个顶着同一身份、状态却各自为政的桥,生成树算不准;互联链路还没被声明成 peer-link,单向隔离不生效,它就是一条普通干道,和双归链路一起把闭合路径提前送进网络。先配置、后连线,是让所有防环角色就位之后,拓扑才闭合——配置顺序本身,就是防环措施的一部分。
1.3 DAD 双主检测链路:先把”裁判”的那条小路铺好
DFS 配对和心跳裁决,都走一个三层 source/peer IP——这个 IP 就绑在 DAD 链路上。所以先把 DAD 的三层口建起来。
DAD 的命门(上篇反复强调):必须物理独立于 peer-link,绝不能共命运。 工程上两种常见落法:
- 直连口方式:单独占一条物理口直连对端,最干净;
- 管理口方式:复用带外管理口(MEth)互通——省一条线,但要确保管理网本身可靠。本次真机环境采用带外管理口作为 DAD。
1 | # ---------- SwitchA---------- |
特别注意:
管理网口、peer-link 接口和堆叠口,在 peer-link 故障但双主检测正常时不会被 error-down,因此走管理口的 DAD 不需要单独配置 m-lag unpaired-port reserved。
做 M-LAG 的双主检测(DAD)时,检测报文千万不能跑到 peer-link 链路上去,否则会造成二层网络瘫痪。
如果直接用物理接口(执行 undo portswitch 变成三层口)配置 IP,报文就是纯三层转发,与二层的 VLAN 毫无关系,也不会和 peer-link 产生任何交集。这种方式最简单、最干净,不会引发任何二层问题。
不推荐用 VLANIF 接口做 DAD!风险在哪?
如果用 VLANIF(比如 VLANIF 100)来配置双主检测的 IP,探测报文就会带着 VLAN 100 的标签在二层网络里跑。这里的关键点在于:peer-link 接口默认是放行所有 VLAN 的。只要 peer-link 也放行了 VLAN 100,DAD 报文就会从 peer-link 过——“裁判”和”被裁判的链路”共了命运,还会引出环路、MAC 地址漂移这类致命问题。如果非要用 VLANIF 100 做双主检测,就必须在 peer-link 接口上把 VLAN 100 屏蔽掉(port vlan exclude 100)。
1.4 DFS Group:让两个大脑配对、选主、并约定二次故障兜底
DFS Group 干三件事:配对(编号相同才配上)、选主(比优先级、再比系统 MAC)、绑定刚才那条 DAD source/peer。
这里必须澄清一个跨厂商方向陷阱:
华为 DFS Group 是”优先级大者为主”(缺省 100,配大的那台当主);而思科、H3C 都是”值小者为主”。方向相反。
华为想让某台当主,就把它的
priority配大。优先级相同才比系统 MAC,此时小者为主(这条三家一致)。
1 | # ---------- SwitchA(设为主:优先级配大)---------- |
1 | # ---- SwitchB(为备:优先级 120,低于 A;注意 source/peer 的 IP 需要对调)----- |
开启二次故障增强功能(dual-active detection enhanced enable)的目的:防止”peer-link 断了之后,主设备又宕机导致业务全断”的极端情况——备机感知到主故障后,会自动拉起被 error-down 的端口接管业务。同时,为避免主设备复活且 peer-link 尚未修复时发生脑裂,配置心跳检测时必须双向指定对端 IP(即 peer 参数)。
验证(部署阶段最该先看的一条命令):
1 | display dfs-group 1 m-lag |
该看到什么算对:Heart beat state 为 OK;两端角色一主一备(A=Master、B=Backup)。若此时配对失败、Causation 显示 NOPEERLINK,别慌——peer-link 还没配,下一步就配。
1.5 peer-link:同步主干道,必须聚合、必须排除业务 VLAN 1
peer-link 是 M-LAG 的命脉(上篇讲了它为什么必须高带宽、必须做聚合——给命脉本身上冗余,防”假性脑裂”)。落地四个硬要求:
- 用 Eth-Trunk(多成员),框式设备成员口跨板部署;
- Eth-Trunk 缺省工作在手工负载分担模式;为提高 M-LAG 的可靠性,peer-link 必须配置为静态 LACP 模式(
mode lacp-static); - 它是两台之间的内部专线,不参与对外的生成树计算;
- 排除 VLAN 1 等无关 VLAN,避免无谓泛洪。
1 | # SwitchA 与 SwitchB 配置完全相同 |
验证:
1 | display dfs-group 1 peer-link # peer-link 口状态 |
该看到什么算对:peer-link 状态 UP;回到上一步再看 display dfs-group 1 m-lag,NOPEERLINK 应消失、配对转为正常。
1.6 M-LAG 成员口:对下游露出的那张统一的脸
主备各自连下游的聚合口,绑同一个 m-lag-id,下游就会把两台的成员口看成同一个聚合组——这就是”演成一台”露出来的接口。
1 | # SwitchA 与 SwitchB 配置完全相同(m-lag-id 必须一致!) |
下游服务器 / 接入交换机侧,做一个普通的 LACP 聚合即可——它根本不知道上面是两台。
验证:
1 | display dfs-group 1 m-lag brief # 各 m-lag-id 的主备/状态 |
某个生产环境下典型的一个返回例如:
1 | * - Local node |
带*星号的代表本端。
M-Lag ID(3 和 5)——这是”对外那张脸”的编号,Interface(Eth-Trunk 3 / 5)——本端参与这场”合演”的演员。注意这列只显示本端的聚合口。这套环境有个工程上很舒服的习惯:m-lag-id 和 Eth-Trunk 编号对齐(3 配 3、5 配 5)。
Port State(Up)——本端这个聚合口自己的状态:物理成员起来了、LACP 协商过了,Status(active(*)-active)——整个回显最有信息量的一列,格式是”本端-对端”。它回答的问题是:这张脸的两半,各自在不在转发?
注意:主备只是”出事时谁听谁的”的裁决序位,平时两台的转发地位完全平等,”备”是法律身份,不是工作状态。
Consistency-check(–)——两端配置一致性检查结果。-- 表示没有触发任何不一致告警。
Failed reason——官方替你枚举的”必须对齐清单”,具体等到下篇排障篇再详细说明。
1.7 三层双活网关:对下游露出的那个统一的网关
到这里二层 M-LAG 已经能跑,服务器的帧能顺畅地上来。但服务器的流量最终要跨网段,它需要一个网关——而且这个网关必须配合两台交换机的”演出”:下游无论把帧 hash 到哪一台,看到的都得是同一个网关,否则戏就穿帮了。
做法是两台共用同一个虚拟网关:相同的 VLANIF IP + 相同的虚拟 MAC。
1 | # SwitchA 与 SwitchB 配置完全相同(IP 与虚拟 MAC 都一致) |
为什么虚拟 MAC 必须相同?回想帧的旅程:服务器发往网关的帧,目的 MAC 是 ARP 学来的网关 MAC。如果两台交换机各用各的系统 MAC,服务器 ARP 表里只会有其中一台的——被 hash 到另一台的帧,目的 MAC 对不上,轻则绕 peer-link、重则行为不可预期。
两台用同一个虚拟 MAC,帧落到哪台,哪台就能理直气壮地收下并完成路由,本地进、本地转,不绕路——这是双活网关”双活”二字的落点:两台同时都是网关,而不是一主一备。
验证:
1 | display interface Vlanif105 # 两台的 Vlanif 都应 Up,MAC 一致 |
该看到什么算对:两台的 Vlanif105 都是 Up,MAC 地址一栏显示的都是 0000-5e00-0011。
到这一步,南向的故事讲完了:服务器双归上来,网关双活接住。但 172.18.3.0/24 里的流量不会只在本网段打转,它们要出去——去防火墙、去外网。网关的北面怎么接?这就是下一节的事。
1.8 北向对接防火墙:为什么用独立三层口,而不是 VLANIF
到目前为止,我们讲的都是 M-LAG 的南向——服务器、接入交换机怎么双归上来。现在换个方向看北向:两台 M-LAG 交换机往上要接防火墙,三层怎么对?
直觉方案往往是”照搬南向的成功经验”:防火墙也做个 Eth-Trunk 双线上联到 M-LAG,交换机侧起 VLANIF 跑 OSPF——既然 M-LAG 能对服务器演成一台,为什么不能对防火墙也演成一台?
能,但不该。
这一节先说结论:北向对接三层设备跑动态路由,推荐放弃 M-LAG,改用两条独立三层链路,让防火墙和两台交换机各建各的 OSPF 邻居。
M-LAG 的”演技”是为二层双归准备的,三层世界里有更好的原生机制——路由协议本身。
北向对接,摆在面前的是两个方案:
方案一:VLANIF over M-LAG(非专业术语,本质为 Eth-Trunk + VLANIF 方式)。防火墙把两个物理口捆成一个 Eth-Trunk,双线下联到 M-LAG——和服务器接入的方式一模一样;交换机侧起 VLANIF 作三层接口,防火墙和这个 VLANIF 建 OSPF 邻居。在防火墙眼里,对面是”一台”交换机、一个邻居。
方案二:独立三层口。防火墙两个物理口不做捆绑,一根线直连 SW1、一根线直连 SW2,各配一段独立的 /30 互联网段,各建一个 OSPF 邻居。在防火墙眼里,对面就是两台交换机、两个邻居。
先看方案一的问题。
第一个问题在报文路径:OSPF 的 Hello 是组播报文,防火墙发出后经 LAG 哈希只会落到其中一条成员链路上,直达一台交换机;另一台要收到,得靠 peer-link 转一手。邻居能建起来,但控制报文的路径不对称、不直观,排障时脑子里要多绕一道弯。
这里稍微解释下。因为OSPF Hello 的输入字段是全程恒定的。我们代入到伪hash函数代码看一下:
1 | key = (10.253.0.2, # src_ip:防火墙 VLANIF 地址,固定 |
五个输入一个都不会变,所以 index 永远是同一个值——可能是 0 也可能是 1,取决于厂商的哈希算法,但一旦定了就不会换。防火墙发出的每一个 Hello、每一个 LSU、每一个 ACK,全部从同一条成员链路出去,直达同一台交换机。这不是概率上的”大概率同一条”,是数学上的必然。
值得一提的是,VLANIF 方式下,OSPF 会话这一条”流”永远单腿,但是业务流量的整体照常双腿走路,即负载均衡处理。
第二个问题更实际,出在故障场景:假设防火墙到 SW1 的那条成员链路断了——LAG 里还剩一条腿,所以 Eth-Trunk 不会 Down,VLANIF 也不会 Down,OSPF 邻居安然无恙,三层完全感知不到这次故障,路由收敛根本不会发生。流量怎么办?靠 M-LAG 机制绕 peer-link 送到对端再转发。也就是说,peer-link 从”控制面通道 + 极端故障时的备份”变成了单链路故障下要常态承载业务流量的转发路径——故障域和带宽压力都被耦合了进来,而这类”链路断了但什么告警都不触发”的静默降级,恰恰是运维最讨厌的故障形态。
再看方案二。同样是防火墙到 SW1 的链路断:物理口 Down,OSPF 邻居立刻 Down,路由随之撤销,防火墙把流量切到 SW2 那条路——检测、收敛、切换,全部由 OSPF 一个机制闭环完成,几秒了结,不依赖任何 M-LAG 逻辑,peer-link 回归它二层同步的本职。
有人担心不捆 LAG 会浪费带宽,其实不会:两条链路等 cost,防火墙到下游天然 ECMP 负载分担,两条 10GE 照样一起跑满,带宽利用率不输 Eth-Trunk。
两个方案的差别,归结起来是一句话:方案一让二层机制(M-LAG)去兜三层的故障,方案二让三层故障由三层机制(OSPF)自己兜——链路断了,前者靠”演”来遮掩,后者靠路由收敛来解决,后者的故障行为清晰、告警明确、路径可预期。
最后回到本系列的那句话:M-LAG 不是把两台设备合并成一台,而是让它们对外演成一台。
为什么要演?
因为南向的观众是服务器、是二层设备,它们没有分辨两台设备的能力,只能给它们看”一台”的假象。
而北向的观众是防火墙,它跑着 OSPF,天生就看得懂”对面有两台设备、两条路”这件事,还能把两条路用得明明白白。
核心区别:对看不懂的观众,才需要演戏;对看得懂的,直接说真话。所以南向用 M-LAG,北向用独立三层口——不是 M-LAG 不好,是这里的观众不需要它。
地址规划如下:
| 互联链路 | 互联网段 | 防火墙侧地址 | 交换机侧地址 |
|---|---|---|---|
| 防火墙 ↔ SW1 | 10.104.1.8/30 | 10.104.1.9 | 10.104.1.10 |
| 防火墙 ↔ SW2 | 10.104.1.12/30 | 10.104.1.13 | 10.104.1.14 |
拓扑图

这套编址背后是三条互联地址规划原则:
专段专用——互联地址统一从专用地址块(本例 10.104.0.0/16)中划取,与业务网段严格隔离。traceroute 里看到 10.104.x.x,不用查台账就知道这一跳是设备互联段。
地址块对应网络层级——10.104 段给出口层互联,10.103 段留给下一层级,看地址段即可定位故障在哪一层。
网段内分配有约定——每个 /30 内,上层设备恒取第一个可用地址(防火墙取 .9、.13),下层取第二个。路由表里看下一跳地址,就能判断对端是谁。
单看每条都微不足道,合起来决定一张网是”规划出来的”还是”长出来的”。
详细配置
交换机 A 配置
1 | interface 10GE1/0/33 |
交换机 B 配置
1 | interface 10GE1/0/33 |
四个细节:
- 网络类型改 p2p,跳过 DR/BDR 选举,邻居秒建,收敛更快——点对点链路上选 DR 本来就是浪费。
- 两台交换机对业务网段的宣告方式必须一致(都用 network)。一台 network、一台 import-route 引入,路由类型一个是区域内一个是外部,OSPF 选路时内部严格优于外部,ECMP 直接失效——这是双人分工配置时最容易踩的坑。
- 防火墙别忘了安全策略:OSPF 报文要在 Local 与互联 zone 之间放行,否则邻居卡在 Init。
- 网关 VLANIF 必须配
silent-interface(本例配置中已加)。network 172.18.3.0 0.0.0.255在宣告网段的同时,也把 OSPF 使能到了 Vlanif105 上。而两台交换机的 Vlanif105 配的是同一个 IP——各自发出的 Hello 会经 peer-link 在 VLAN 105 里送到对方手上,而这些报文的源地址与对方自己的接口地址完全相同,只会被当作地址冲突/非法报文丢弃,日志里平白多出一堆告警,这个”邻居”也永远建不起来,纯属噪音与隐患。silent-interface Vlanif105让 OSPF 保留对 172.18.3.0/24 的宣告,但不在该接口上收发任何协议报文——一条命令,既保住路由宣告,又掐掉告警。双活网关跑 OSPF,这条不是可选优化,是必配项。
验证
防火墙侧查看 OSPF 邻居状态,显示已通过 GigabitEthernet0/0/6、GigabitEthernet0/0/7 分别与两台交换机建立 OSPF 邻居关系,邻居 Router ID 分别为 3.3.3.3、3.3.3.4,状态均为 Full,说明 OSPF 邻接关系建立成功,动态路由协议运行正常。
1 | display ospf peer brief # 站在防火墙角度看 |
接下来我们验证ECMP等价路由
1 | display ip routing-table 172.18.3.0 |
看到业务网段出现两个下一跳,ECMP 生效,北向三层对接完成。但此刻的组网还留着一个黑洞场景:SW1 的上行链路断了,南向 LAG 哈希到 SW1 的那一半流量,在 SW1 的路由表里找不到出口。这就是下一节逃生链路要解决的问题。
1.9 三层逃生链路:补上最后一个黑洞场景
上一节结尾留了个洞,现在来补。
先把不配逃生链路会发生什么,推演到帧级别。
场景:SwitchA 与防火墙之间的 10GE1/0/33 链路断了——光模块烧了、尾纤被踩了,都行。此时 SwitchA 本身好好的,它下联服务器的 M-LAG 成员口也好好的。看两个方向的反应:
北向(防火墙视角)自愈得很漂亮:物理口 Down,OSPF 邻居随之 Down,防火墙撤销经 SwitchA 的路由,到 172.18.3.0/24 的流量全部切到 SwitchB 那条路——OSPF 几秒内闭环,无需任何人干预。
南向(服务器视角)就没这么幸运了。服务器的 bond 做 LACP hash 时,依据的是自己到两台交换机的成员链路状态。
而 SwitchA 的成员口还是 Up 的,LACP 完全不知道 SwitchA 的”后门”已经断了。于是 hash 结果不变,大约一半的流(取决于五元组分布)继续被送往 SwitchA。这些帧到达 SwitchA、命中虚拟 MAC、进入三层查表——到防火墙方向的路由已经随邻居一起消失了,查表未命中,丢弃。
参考上篇(原理篇)的图和文字描述。
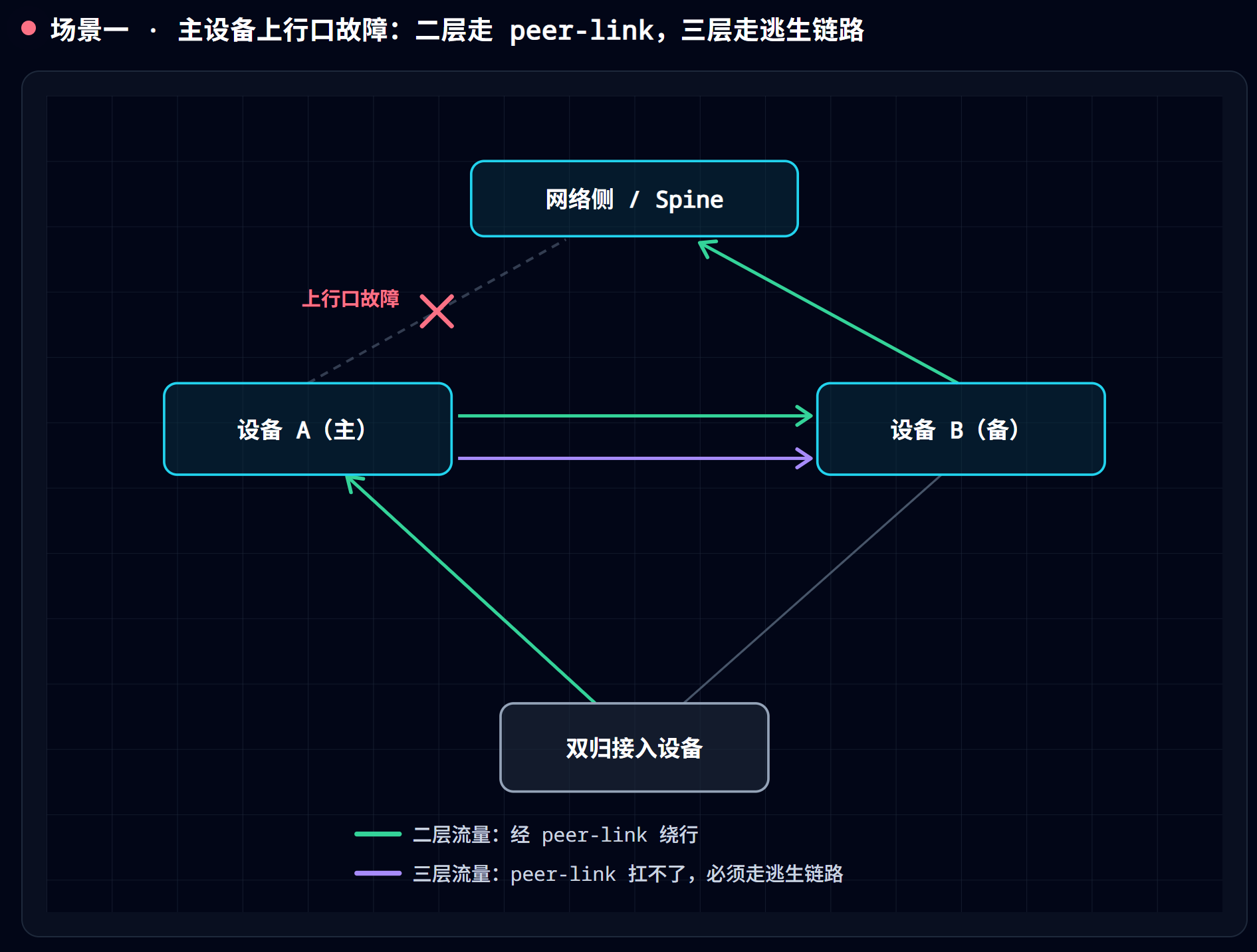
这里二层和三层的处理截然不同,是最容易栽跟头的地方(上篇(原理篇),常看常新)。
- 二层接入:主设备上行口坏了,它把流量从 peer-link 转给备设备,备设备从自己的上行口发出去。纯二层桥接,而 peer-link 本来就是条二层链路,天生支持——“走 peer-link”成立。
- 三层接入:到达主设备的上行流量是要被路由出去的,而 peer-link 是二层链路,默认不在两台设备之间承载三层路由邻居/路由。主设备自己的出口路由失效后,它没有一条”经备设备出去”的路由,流量直接被路由黑洞丢掉。
注意这个故障的三个特征:它只黑一半(另一半 hash 到 SwitchB 的流完好,所以业务表现是”时通时不通”,比全断更难排查);它不会自愈(LACP 探测的是成员链路本身,永远探测不到交换机背后的上行断链);它持续到人工干预为止。这就是上篇说的三层黑洞,在真实拓扑里的样子。
有人会问:peer-link 不是还在吗?流量确实过得去,peer-link 转发三层单播本来就是 M-LAG 的日常。
但问题不在转发面,而在控制面,核心问题在于:peer-link 是纯二层链路,上面没有 IP、没有路由邻居,SW1 的路由表里永远算不出一条”经 peer-link 绕行”的路。
路是通的,地图上没有,导航就永远不会带你走。要让绕行路径进路由表,就得有一段三层互联和一个路由邻居,这就是逃生链路。
至于为什么不直接在 peer-link 上叠个 VLANIF 凑数,是另一个层面的理由:peer-link 身上已经背着协议同步和防环隔离,再把三层兜底也压上去,两套保命机制就共享同一个故障点了。
逃生链路解决的正是这个”知道路由、缺条路径”的问题。在两台交换机之间拉一条独立的三层互联,跑 OSPF:正常时它只是 LSDB 里一条更劣的候选路径,平时不进路由表、不承载业务流量。
SwitchA 上行一断,SPF 重算,SwitchA 立刻学到”经 SwitchB 绕行到防火墙”的路由:被 hash 过来的那一半流量多走一跳(SwitchA → 逃生链路 → SwitchB → 防火墙),但一个包都不丢。
配置(OSPF 进程已在上一节创建,这里只追加逃生接口):
1 | # SwitchA:三层逃生链路(与 peer-link 分开,别叠在 peer-link 的 VLANIF 上) |
关于 ospf cost 100 多说一句:其实不调,绕行路径也因为多一跳而天然劣于直连,平时不会被选中。显式调大是防御性设计——防止将来有人改了参考带宽或接口 cost,让逃生链路意外变成常规转发路径,把”备胎”开成了”主力”。
另外一个特别注意的点:VLANIF105 跑 OSPF 的一个隐患,两台交换机 VLANIF105 配了相同 IP 172.18.3.254,而 network 172.18.3.0 0.0.0.255 会把 OSPF 使能到这个接口上——两台会经 peer-link 在 VLAN 105 里互收对方的 Hello,源地址与本机相同,通常会刷 duplicate address 类告警日志。标准做法是在 ospf 1 下加 silent-interface Vlanif105(宣告网段但不收发协议报文)。
如果不加的话,我们可以通过display ospf 1 error命令,发现IP: received my own packet会逐渐增大
1 | display ospf 1 error |
验证分两步,静态看表,动态拔线:先静态看表
1 | display ospf peer |
该看到什么算对: 2 个 Full 邻居——防火墙(经 10GE1/0/33)+ SW2(经逃生链路 10GE1/0/40),都在 area 0.0.0.0;少了 SW2 那个,逃生链路白配。
接下来我们动态拔线。我们将交换机 A 到防火墙的上联口 10GE1/0/33 shutdown,此时我们查找路由表。
1 | display ip routing-table 10.104.1.12 |
此时路由表已经生效,我们在拔线前一直将服务器动态 ping,实验证明没有丢包。
实验做到这里,值得停下来想一个问题:这些配置到底给谁带来了什么?
先看防火墙。答案可能出乎意料:动态路由并没有给防火墙多出什么路由。它的两条等价路径是两条物理上行决定的,写两条等价静态路由一样能 ECMP。OSPF 改变的不是路由的数量,而是路由的生命周期:链路断,路由自动撤销;链路恢复,路由自动回归。静态路由是刻在石头上的地图,动态路由是实时更新的导航。刚才实验里防火墙从两条 ECMP 收敛为一条、又自动恢复,靠的正是这个。
再看交换机,这边才真正多出了一条通道——而且静态路由养不起它。逃生链路需要的行为是三段式的:平时隐身、故障上位、恢复退位。静态路由做不到:它无条件生效,平时就会与直连路径打架。而这个条件性恰恰是 SPF 天然赠送的——绕行路径一直躺在 LSDB 里,直连活着它永远算不赢,直连一死它就是新的最短路,自动上表接管。
一句话总结:动态路由在这个组网里的产出,不是更多的路由,而是会随拓扑生死的路由——防火墙的 ECMP 因此能自愈,交换机的逃生通道因此能隐身。这也回答了”小组网为什么值得跑动态路由”:我们要的不是路由条目的数量,而是它的生命周期管理。
小结:这套组网的故障底牌
三节配完(双活网关 → 北向对接 → 逃生链路),整个组网每一类故障都有了明确的兜底机制,列一张表收进工具箱:
| 故障场景 | 谁来发现 | 谁来兜底 | 流量表现 |
|---|---|---|---|
| 服务器→交换机某条成员链路断 | LACP(物理口 Down) | bond/LAG 把流量压到另一条腿 | 秒级切换,服务器无感 |
| 交换机→防火墙某条上行断 | OSPF(邻居 Down) | 北向:防火墙 ECMP 收编到另一路;南向:逃生链路绕行 | OSPF 收敛级抖动,不黑洞 |
| peer-link 断 | DFS 双主检测(心跳仲裁) | 备设备 Error-Down 全部 M-LAG 成员口,流量归主 | 半程切换,依赖心跳链路健在 |
| 单台交换机整机宕 | LACP + OSPF 同时发现 | 另一台独立扛全量(南向 LAG 收敛 + 北向路由收敛) | 秒级,单台需能承载全部带宽 |
看这张表能发现一个清晰的分工:南向的故障靠 M-LAG 的”演”来兜(LACP 看到的永远是一台设备),北向的故障靠 OSPF 的”真”来兜(防火墙清楚地知道对面是两台)。二层演戏,三层说真话,各管各的故障域——这也是为什么北向我们最终没有选择把 M-LAG 延伸上去。
1.10 部署收尾:一次”全身体检”
全部配完,跑一遍体检清单,逐项核对而不是”看着像 Up 就完事”:
1 | display dfs-group 1 m-lag # ① 配对正常、心跳 OK、一主一备 |
第②条最容易被跳过、又最爱出事。 M-LAG 两端配置不一致(VLAN、MTU、聚合模式、m-lag-id 等对不齐)是头号部署坑——一致性检查就是专门替你比对两台的。部署一定跑、变更后也要再跑。
二、维护:让它一直”演”下去,别穿帮
部署完只是”演起来了”,维护是”一直演下去不露馅”。维护就两类活:怎么安全地升级,和平时怎么巡检确认它还在好好演。
2.1 升级”接力赛”:M-LAG 双脑独立换来的最大红利
上篇说过,M-LAG 相对堆叠最大的好处之一就是升级无感——因为两个控制平面独立,可以一台一台轮流升,另一台扛着全部流量。这就是”接力赛”:
先升一台,它重启期间另一台扛下 100% 的流量;升好上线、确认表项追平之后,再升另一台。全程业务不中断。
落地纪律(每一棒交接前都要”确认接棒人站稳了”再松手):
- 先升备设备(影响面小)。升级前确认主设备能独立扛全量:
display interface brief看主侧上行/成员口都 Up、带宽有余量。 - 备设备升级重启——此时它的成员口短暂离线,主设备独立转发,下游服务器靠 LACP 自动把流量压到主侧那条腿(服务器无感,上篇延伸思考讲过)。
- 备升完上线,关键一步:等表项同步追平再继续。看
display dfs-group 1 m-lag配对恢复、display mac-address/display arp规模与对端一致,再动下一台。 - 主备角色调换、重复升另一台。
⚠️ 升级的具体命令和兼容版本务必对着设备型号的《升级指导书》走,本文只讲”接力”这个方法论骨架——它才是 M-LAG 升级和堆叠升级的本质区别:堆叠是”一个大脑、升级有整体中断风险”,M-LAG 是”两个大脑、轮流升、零中断”。
2.2 日常巡检:盯住这几个”健康灯”
巡检不用看一百条命令,盯死下面这几盏灯,任何一盏不对就说明”演出快穿帮了”:
| 看什么 | 命令 | 健康长什么样 |
|---|---|---|
| DFS 配对 & 心跳 | display dfs-group 1 m-lag |
配对正常、Heart beat state: OK、一主一备 |
| 两端配置一致性 | display dfs-group consistency-check status |
success(变更后必查) |
| peer-link | display dfs-group 1 peer-link |
Up;成员口无频繁 up/down |
| 成员口 | display dfs-group 1 node 1 m-lag brief |
各 m-lag-id 双侧 Up、都在转发 |
| DAD 心跳口 | display dfs-group 1 node |
在线;且物理上确实独立于 peer-link |
| 表项规模 | display mac-address / display arp |
两台规模相当(同步正常) |
2.3 变更纪律:动配置时的顺序与红线
- 增减成员口:两台必须同步改、绑同一 m-lag-id;改完立刻做一次配置一致性检查。
- 改 DFS 优先级会触发重新选主(缺省行为),可能带来一次主备切换瞬断。若某些场景(如与 NAC 叠加)不希望被动回切,可配
dfs-group state switchover disable关掉角色回切,让主备固定。 - 红线:DAD 链路必须始终物理独立于 peer-link。若 DAD 走的是业务物理口,必须配
m-lag unpaired-port reserved,保证 peer-link 故障时”裁判口”绝不被 error-down(管理网口、peer-link 接口和堆叠口天然豁免,无需该命令——本文的管理口方案即属此类)。裁判一旦被关,脑裂就没人裁了。
总结:部署与维护,是同一件事的两个时态
回看整篇你会发现,说的是同一句话:
部署 = 把”对外一台”按依赖顺序搭出来(先让两脑配对、再同步、再露脸、最后补三层);
维护 = 让这张脸一直在、别穿帮(接力升级守住”零中断”,巡检守住”两台一致”)。
而它们共同的那条主线,还是上篇那一句——
对外一台,对内两台;同步靠 peer-link,裁决靠 DAD。
至于第三个时态——穿帮了怎么救——排障与逐包的流量推演,下篇见:排障不是碰运气,是沿着流量走一遍。